




The content below is taken from the original ( Serverless from the ground up: Connecting Cloud Functions with a database (Part 3)), to continue reading please visit the site. Remember to respect the Author & Copyright.
A few months have passed since Alice first set up a central document repository for her employer Blueprint Mobile, first with a simple microservice and Google Cloud Functions (part 1), and then with Google Sheets (part 2). The microservice is so simple to use and deploy that other teams have started using it too: the procurement team finds the system very handy for linking each handset to the right invoices and bills, while the warehouse team uses the system to look up orders. However, these teams work with so many documents that the system is sometimes slow. And now Alice’s boss wants her to fix it to support these new use cases.
Alice, Bob, and Carol are given a few days to brainstorm how to improve their simple team hack and turn it into a sustainable corporate resource. So they decide to store the data in a database, for better scaling, as well as to be able to customize it for new use cases in the future.
Alice consults the decision flow-chart for picking a Google Cloud storage product. Her data is structured, won’t be used for analytics, and isn’t relational. She has a choice of Cloud Firestore or Cloud Datastore. Both would work fine, but after reading about the differences between them, she decides to use Cloud Firestore, a flexible, NoSQL database popular for developing web and mobile apps. She likes that Cloud Firestore is a fully managed product—meaning that she won’t have to worry about sharding, replication, backups, database instances, and so on. It also fits well with the serverless nature of the Cloud Functions that the rest of her system uses. Finally, her company will only pay for how much they use, and there is no minimum cost—her app’s database use might even fit within the free quota!
First she needs to enable Firestore in the GCP Console. Then, she follows the docs page recommendation for new server projects and installs the Node client library for the Cloud Datastore API, with which Firestore is compatible:
Now she is ready to update her microservice code. The functions handsetdocs() and handleCors() remain the same. The function getHandsetDocs() is where all the action is. For optimal performance, she makes Datastore a global variable for reuse in future invocations. On the query line, she asks for all entities of type Doc, ordered by the handset field. At the end of the function she returns the zeroth element of the result, which holds the entities.
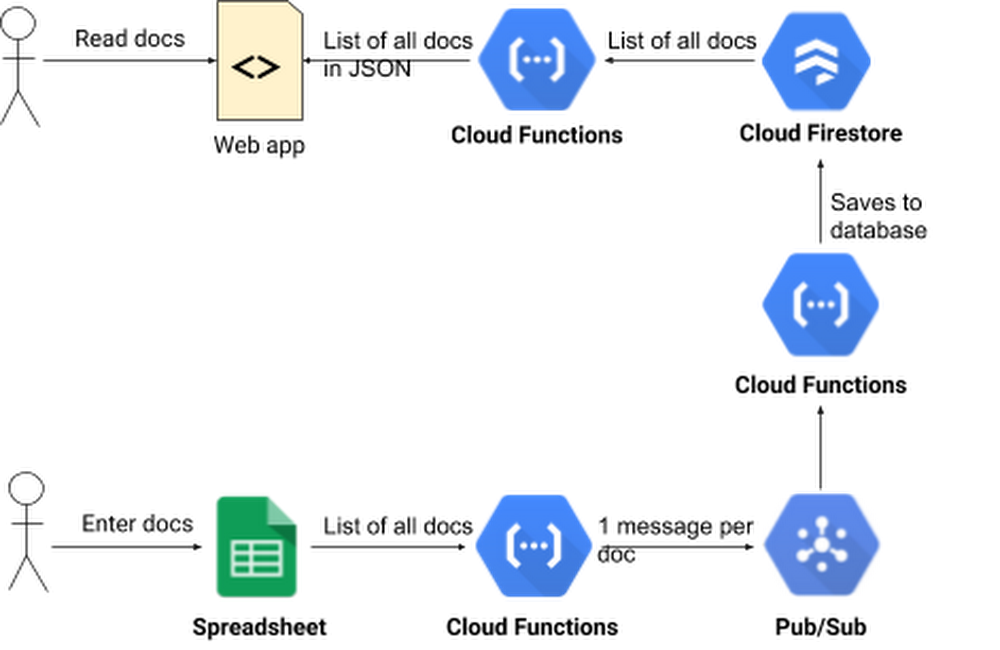
When she has deployed the function, Alice runs into Bob again. Bob is excited about putting the data in a safer place, but wonders how his team will enter new docs in the system. The technicians, and everyone else at the company, have grown used to using the Sheet.
One way solution is to write a function that reads all the rows in the spreadsheet, loops over them and saves each one to the datastore. But what if there’s a failure before all the database operations have executed? Some records will be in the datastore, while others won’t. Alice does not want to build complex logic for detecting such a failure, figuring out which records weren’t copied, and retrying those.
Then she reads about Cloud Pub/Sub, a service for ingesting real-time event streams, and an important tool when building event-driven computing systems. She realizes she can write code to read all the docs from the spreadsheet, and then publish one Pub/Sub message per doc. Then, another microservice (also built in Cloud Functions) is triggered by the Pub/Sub messages that reads the doc found in the Pub/Sub message and writes it to the datastore.
First Alice goes to Pub/Sub in the console and creates a new topic called IMPORT. Then she writes the function that publishes one Pub/Sub message per spreadsheet record. It calls getHandsetDocsFromSheet() to get all the docs from the spreadsheet. This function is really just a renamed version of the getHandsetDocs() function from part 2 of this series. Then the function calls publishPubSubMessages() which publishes one Pub/Sub message per doc.
The publishPubSubMessages() function loops over the docs and publishes one Pub/Sub message for each one. It returns when all messages have been published.
Alice then writes the function that is triggered by these Pub/Sub messages. The function doesn’t need any looping because it is invoked once for every Pub/Sub message, and every message contains exactly one doc.
The function starts by extracting the JSON structure from the Pub/Sub message. Then it creates a Datastore instance if one isn’t available from the last time it ran. Datastore save operations need a key object and a data object. Alice’s code makes doc.id the key. Then she deletes the id property from doc. That way another id column will not be created when she calls save(). If there’s a record with the given id, it is updated. If there isn’t, a new record is created. Then the function returns the result of the save() call, so that the result of the operation (success or failure) gets captured in the log, along with any error messages.
Finally, there needs to be a way to start the data export from the spreadsheet to the database. That is done by hitting the URL for the startImport() function above. In theory, Alice or Bob could do that by pasting that URL into their browser, but that’s awkward. It would be better if any employee could trigger the data export when they are done editing the spreadsheet.
Alice opens the spreadsheet, selects the Tools menu and clicks Script Editor. By entering the Apps Script code below she creates a new menu named “Data Import” in the spreadsheet. It has a single menu item, “Import data now”. When the user selects that menu item, the script hits the URL of the startImport() function, which starts the process for importing the spreadsheet into the database.

Alice takes a moment to consider the system she has built:
-
An easy-to-use data entry front-end using Sheets.
-
A robust way to get spreadsheet data into a database, which scales well and has a good response time.
-
A microservice that serves the whole company as a source of truth for documents.
And it all took less than 100 lines of Cloud Functions code to do it! Alice proudly calls this version 1.0 of the microservice, and calls it a day. Meanwhile, Alice’s co-workers are grateful for her initiative, and impressed by how well she represented her team.
You too, can be a hero in your organization, by solving complex business integration problems with the help of intuitive, easy-to-use serverless computing tools. We hope this series has whetted your appetite for all the cool things you can do with some basic programming skills and tools like Cloud Functions, Cloud Pub/Sub and Apps Script. Follow the Google Cloud Functions Quickstart and you’ll have your first function deployed in minutes.