The content below is taken from the original ( The Wide World of Microsoft Windows on AWS), to continue reading please visit the site. Remember to respect the Author & Copyright.
You have been able to run Microsoft Windows on AWS since 2008 (my ancient post, Big Day for Amazon EC2: Production, SLA, Windows, and 4 New Capabilities, shows you just how far AWS come in a little over a decade). According to IDC, AWS has nearly twice as many Windows Server instances in the cloud as the next largest cloud provider.
Today, we believe that AWS is the best place to run Windows and Windows applications in the cloud. You can run the full Windows stack on AWS, including Active Directory, SQL Server, and System Center, while taking advantage of 61 Availability Zones across 20 AWS Regions. You can run existing .NET applications and you can use Visual Studio or VS Code build new, cloud-native Windows applications using the AWS SDK for .NET.
Wide World of Windows
Starting from this amazing diagram drawn by my colleague Jerry Hargrove, I’d like to explore the Windows-on-AWS ecosystem in detail:
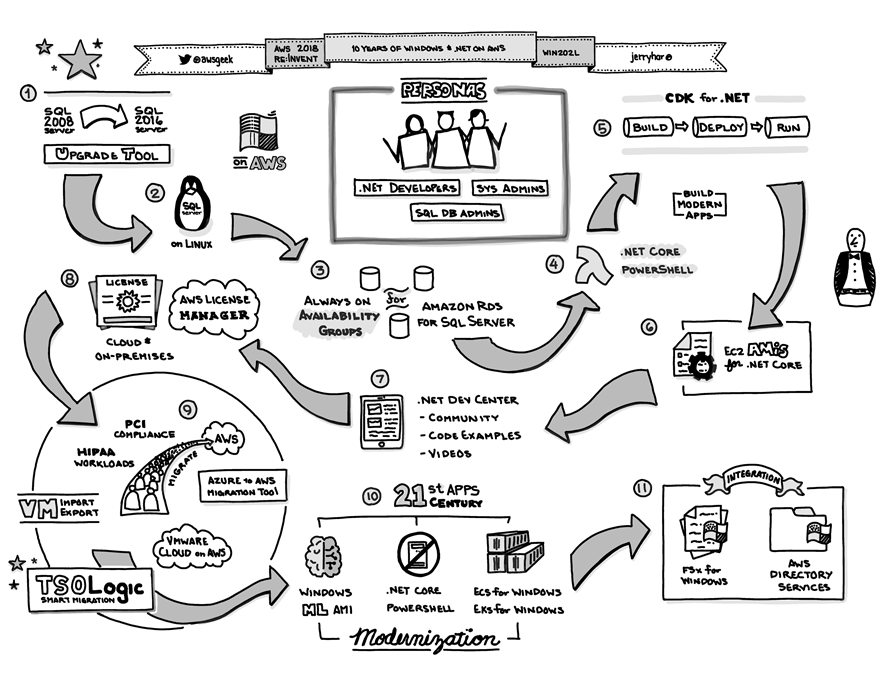
1 – SQL Server Upgrades
AWS provides first-class support for SQL Server, encompassing all four Editions (Express, Web, Standard, and Enterprise), with multiple version of each edition. This wide-ranging support has helped SQL Server to become one of the most popular Windows workloads on AWS.
The SQL Server Upgrade Tool (an AWS Systems Manager script) makes it easy for you to upgrade an EC2 instance that is running SQL Server 2008 R2 SP3 to SQL Server 2016. The tool creates an AMI from a running instance, upgrades the AMI to SQL Server 2016, and launches the new AMI. To learn more, read about the AWSEC2-CloneInstanceAndUpgradeSQLServer action.
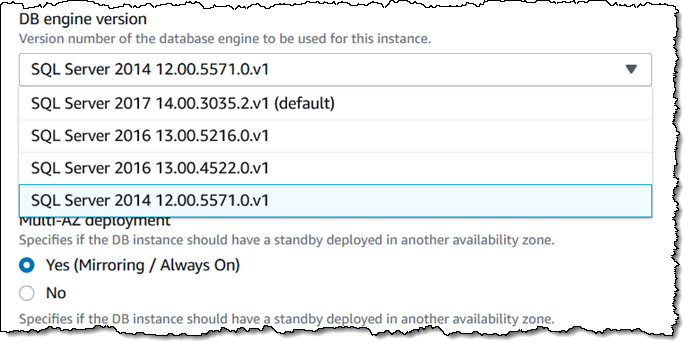
Amazon RDS makes it easy for you to upgrade your DB Instances to new major or minor upgrades to SQL Server. The upgrade is performed in-place, and can be initiated with a couple of clicks. For example, if you are currently running SQL Server 2014, you have the following upgrades available:
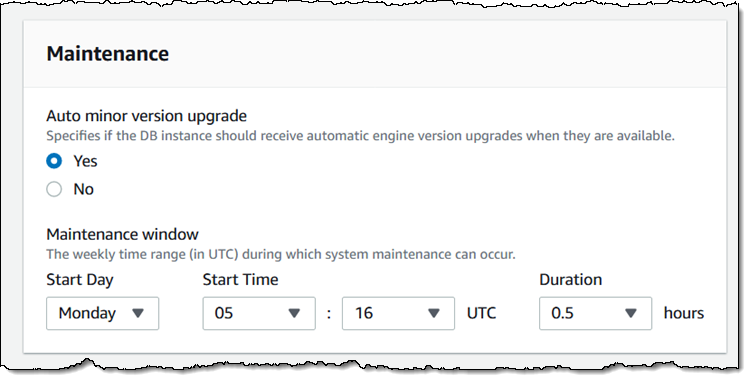
You can also opt-in to automatic upgrades to new minor versions that take place within your preferred maintenance window:
Before you upgrade a production DB Instance, you can create a snapshot backup, use it to create a test DB Instance, upgrade that instance to the desired new version, and perform acceptance testing. To learn more, about upgrades, read Upgrading the Microsoft SQL Server DB Engine.
2 – SQL Server on Linux
If your organization prefers Linux, you can run SQL Server on Ubuntu, Amazon Linux 2, or Red Hat Enterprise Linux using our License Included (LI) Amazon Machine Images. Read the most recent launch announcement or search for the AMIs in AWS Marketplace using the EC2 Launch Instance Wizard:
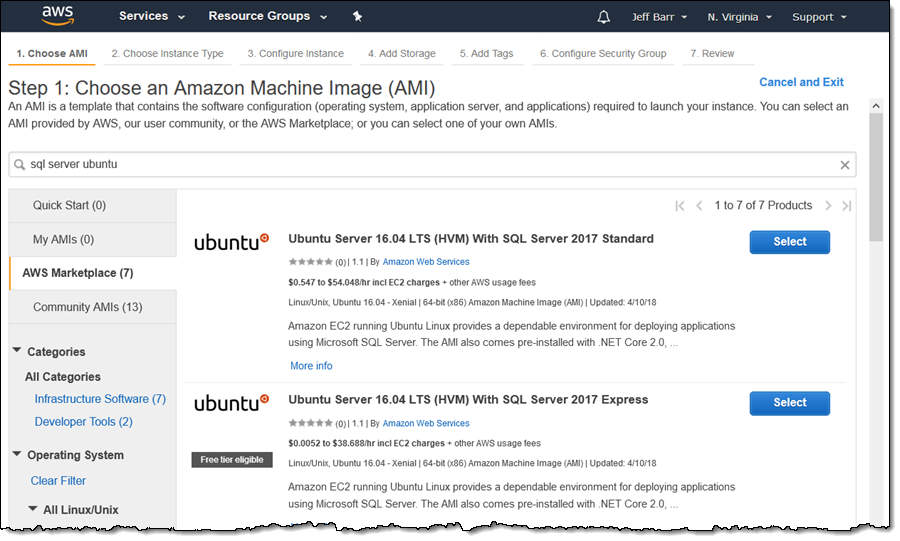
This is a very cost-effective option since you do not need to pay for Windows licenses.
You can use the new re-platforming tool (another AWS Systems Manager script) to move your existing SQL Server databases (2008 and above, either in the cloud or on-premises) from Windows to Linux.
3 – Always-On Availability Groups (Amazon RDS for SQL Server)
If you are running enterprise-grade production workloads on Amazon RDS (our managed database service), you should definitely enable this feature! It enhances availability and durability by replicating your database between two AWS Availability Zones, with a primary instance in one and a hot standby in another, with fast, automatic failover in the event of planned maintenance or a service disruption. You can enable this option for an existing DB Instance, and you can also specify it when you create a new one:
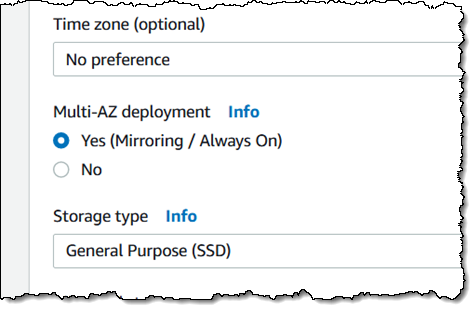
To learn more, read Multi-AZ Deployments Using Microsoft SQL Mirroring or Always On.
4 – Lambda Support
Let’s talk about some features for developers!
Launched in 2014, and the subject of continuous innovation ever since, AWS Lambda lets you run code in the cloud without having to own, manage, or even think about servers. You can choose from several .NET Core runtimes for your Lambda functions, and then write your code in either C# or PowerShell:
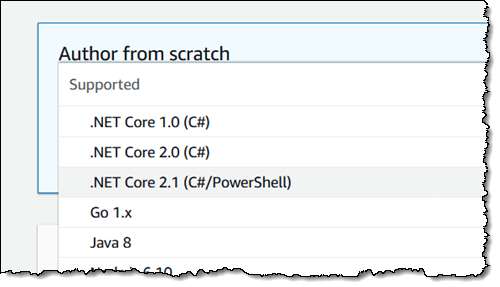
To learn more, read Working with C# and Working with PowerShell in the AWS Lambda Developer Guide. Your code has access to the full set of AWS services, and can make use of the AWS SDK for .NET; read the Developing .NET Core AWS Lambda Functions post for more info.
5 – CDK for .NET (Developer Preview)
The Developer Preview of the AWS CDK (Cloud Development Kit) for .NET lets you define your cloud infrastructure as code and then deploy it using AWS CloudFormation. For example, this code (stolen from this post) will generate a template that creates an Amazon Simple Queue Service (SQS) queue and an Amazon Simple Notification Service (SNS) topic:
var queue = new Queue(this, "MyFirstQueue", new QueueProps
{
VisibilityTimeoutSec = 300
}
var topic = new Topic(this, "MyFirstTopic", new TopicProps
{
DisplayName = "My First Topic Yeah"
});
6 – EC2 AMIs for .NET Core
If you are building Linux applications that make use of .NET Core, you can use use our Amazon Linux 2 and Ubuntu AMIs. With .NET Core, PowerShell Core, and the AWS Command Line Interface (CLI) preinstalled, you’ll be up and running— and ready to deploy applications—in minutes. You can find the AMIs by searching for core when you launch an EC2 instance:
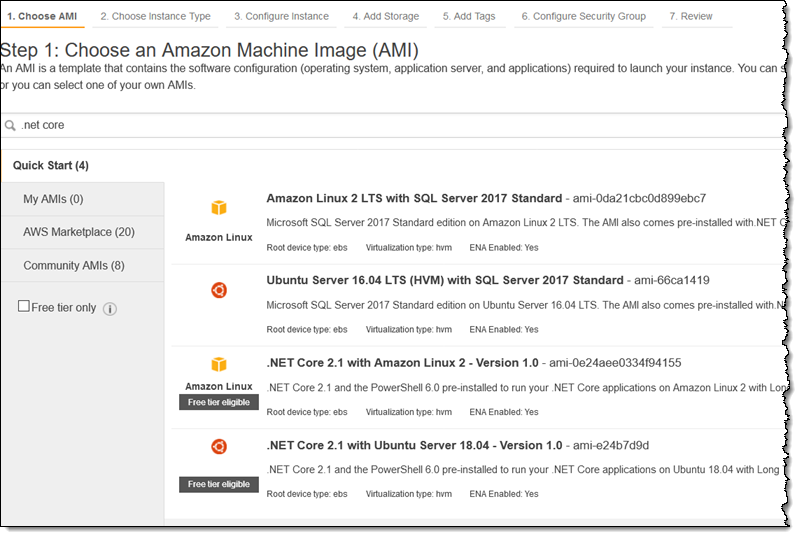
7 – .NET Dev Center
The AWS .Net Dev Center contains materials that will help you to learn how design, build, and run .NET Applications on AWS. You’ll find articles, sample code, 10-minute tutorials, projects, and lots more:
8 – AWS License Manager
We want to help you to manage and optimize your Windows and SQL Server applications in new ways. For example, AWS License Manager helps you to manage the licenses for the software that you run in the cloud or on-premises (read my post, New AWS License Manager – Manage Software Licenses and Enforce Licensing Rules, to learn more). You can create custom rules that emulate those in your licensing agreements, and enforce them when an EC2 instance is launched:
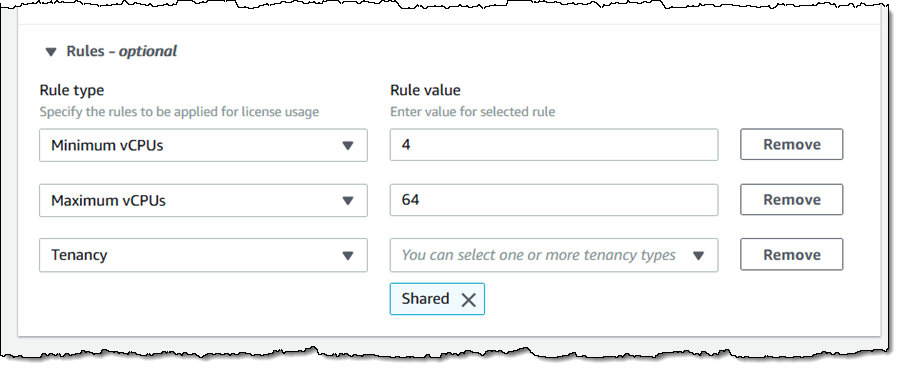
The License Manager also provides you with information on license utilization so that you can fine-tune your license portfolio, possibly saving some money in the process!
9 – Import, Export, and Migration
You have lots of options and choices when it comes to moving your code and data into and out of AWS. Here’s a very brief summary:
TSO Logic – This new member of the AWS family (we acquired the company earlier this year) offers an analytics solution that helps you to plan, optimize, and save money as you make your journey to the cloud.
VM Import/Export – This service allows you to import existing virtual machine images to EC2 instances, and export them back to your on-premises environment. Read Importing a VM as an Image Using VM Import/Export to learn more.
AWS Snowball – This service lets you move petabyte scale data sets into and out of AWS. If you are at exabyte scale, check out the AWS Snowmobile.
AWS Migration Acceleration Program – This program encompasses AWS Professional Services and teams from our partners. It is based on a three step migration model that includes a readiness assessment, a planning phase, and the actual migration.
10 – 21st Century Applications
AWS gives you a full-featured, rock-solid foundation and a rich set of services so that you can build tomorrow’s applications today! You can go serverless with the .NET Core support in Lambda, make use of our Deep Learning AMIs for Windows, host containerized apps on Amazon ECS, AWS Fargate, or Amazon EKS, and write code that makes use of the latest AI-powered services. Your applications can make use of recommendations, forecasting, image analysis, video analysis, text analytics, document analysis, text to speech, translation, transcription, and more.
11 – AWS Integration
Your existing Windows Applications, both cloud-based and on-premises, can make use of Windows file system and directory services within AWS:
Amazon FSx for Windows Server – This fully managed native Windows file system is compatible with the SMB protocol and NTFS. It provides shared file storage for Windows applications, backed by SSD storage for fast & reliable performance. To learn more, read my blog post.
AWS Directory Service – Your directory-aware workloads and AWS Enterprise IT applications can use this managed Active Directory that runs in the AWS Cloud.
Join our Team
If you would like to build, manage, or market new AWS offerings for the Windows market, be sure to check out our current openings. Here’s a sampling:
Senior Digital Campaign Marketing Manager – Own the digital tactics for product awareness and run adoption campaigns.
Senior Product Marketing Manager – Drive communications and marketing, create compelling content, and build awareness.
Developer Advocate – Drive adoption and community engagement for SQL Server on EC2.
Learn More
Our freshly updated Windows on AWS and SQL Server on AWS pages contain case studies, quick starts, and lots of other useful information.
— Jeff;
















 Computers have changed the way we live our lives. They have found a place for themselves in every walk of our life. In the recent past, artificial intelligence and machine learning have given way to increased automation. Despite the development,
Computers have changed the way we live our lives. They have found a place for themselves in every walk of our life. In the recent past, artificial intelligence and machine learning have given way to increased automation. Despite the development,
 GoPro cameras are widely used pocket-sized camera device popular among adventures, surfers, athletes, travelers and boggers for action photography. They are great for rugged use and is ideal for capturing videos when you are in beach, mountain, snow, diving into
GoPro cameras are widely used pocket-sized camera device popular among adventures, surfers, athletes, travelers and boggers for action photography. They are great for rugged use and is ideal for capturing videos when you are in beach, mountain, snow, diving into
 The past few years Microsoft has been more transparent than ever. The Redmond giant had published a page which lists down all known issues, date when the issue was resolved, information on when they were resolved, and support time left
The past few years Microsoft has been more transparent than ever. The Redmond giant had published a page which lists down all known issues, date when the issue was resolved, information on when they were resolved, and support time left

 Minecraft is celebrating its 10th birthday by making its Classic version easily playable on web browsers. You don't need to download any files to make it work, and you don't have to pay a cent for access. Since Classic was only the second phase in th…
Minecraft is celebrating its 10th birthday by making its Classic version easily playable on web browsers. You don't need to download any files to make it work, and you don't have to pay a cent for access. Since Classic was only the second phase in th…














 Creating a Windows Virtual Desktop Tenant (Image Credit: Russell Smith)
Creating a Windows Virtual Desktop Tenant (Image Credit: Russell Smith) Creating a Windows Virtual Desktop Tenant (Image Credit: Russell Smith)
Creating a Windows Virtual Desktop Tenant (Image Credit: Russell Smith) Creating a Windows Virtual Desktop Tenant (Image Credit: Russell Smith)
Creating a Windows Virtual Desktop Tenant (Image Credit: Russell Smith) Creating a Windows Virtual Desktop Tenant (Image Credit: Russell Smith)
Creating a Windows Virtual Desktop Tenant (Image Credit: Russell Smith)



 If you often play games on your computer, you should check out Game Backup Monitor. It will help you automatically backup the configuration files of your games. It is a free and open-source software that is available for multiple computer
If you often play games on your computer, you should check out Game Backup Monitor. It will help you automatically backup the configuration files of your games. It is a free and open-source software that is available for multiple computer




