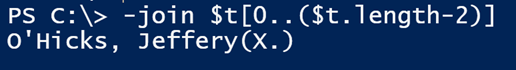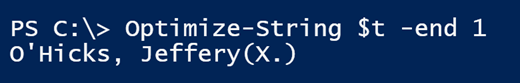The content below is taken from the original ( ROOL releases updated Git Beta), to continue reading please visit the site. Remember to respect the Author & Copyright.
Up until now, I have regarded the Git client from ROOL as an exciting development but not exiting development but really that useful… All that has changed with the latest version!
The killer new new feature is support for pull and push. Previously you could not easily reference your existing repos or export from your system. Now you can!
You also get a selection of useful bug fixes and features including help in the iconbar menu.
Git is still being tested (looks good here) but I am sure ROOL would also be happy to recruit additional testers if you are interested….
The content below is taken from the original ( It’s time to design for repair), to continue reading please visit the site. Remember to respect the Author & Copyright.
A conversation with Jude Pullen Trying to repair almost anything can be a frustrating exercise. Repair is made more difficult by the way devices are designed and the ability to repair a device could be improved greatly if different design decisions were made. This moment in time demands a new generation of designers, engineers and […]
Linux’s compgen command is not actually a Linux command. In other words, it’s not implemented as an executable file, but is instead a bash builtin. That means that it’s part of the bash executable. So, if you were to type “which compgen”, your shell would run through all of the locations included in your $PATH variable, but it just wouldn’t find it.
$ which compgen
/usr/bin/which: no compgen in (.:/home/shs/.local/bin:/home/shs/bin:/usr/local/bin:
/usr/bin:/usr/local/sbin:/usr/sbin)
Obviously, the which command had no luck in finding it.
If, on the other hand, you type “man compgen”, you’ll end up looking at the man page for the bash shell. From that man page, you can scroll down to this explanation if you’re patient enough to look for it.
The cloud is constantly evolving, making upskilling and reskilling an important time investment. During November, we are featuring no-cost, on-demand and live training videos and courses for both technical and non-technical roles. Spanning introductory to more advanced levels, training options cover three of our most popular topics: generative AI, the basics of Google Cloud, and Google Cloud certification preparation.
Take a look at the suggested training below to move forward in your learning journey. You can even earn learning credentials to share on your developer profile, resumé and LinkedIn profile. Keep reading to get started.
Understanding Google Cloud foundational content for any role
Here are some options for learners who are either technical practitioners, or in tech-adjacent roles, like HR, sales, and marketing that work with Google Cloud products, or with teams who do.
These foundational-level courses help you learn about Google Cloud technology and how it can benefit your organization. Comprised of videos and quizzes, you should be able to finish them during part of a morning or afternoon when you have a bit of extra time. Complete all four courses below to help you prepare for the Cloud Digital Leader certification.
We have a mix of options to help you learn about generative AI as this area of technology becomes more available.
Introduction to Generative AI – No technical background required. This learning path explains generative AI, large learning models, responsible AI, and applying AI principles with Google Cloud.
Gen AI Bootcamp – This is a series of three sessions for developers who want to explore gen AI solutions. As the month goes on, the topics progress from introductory to advanced, and you can jump in at any time. The sessions are running as live events throughout November — register here to reserve your spot. They will also be available on-demand.
Prepare for Google Cloud Certification with no-cost resources
Earning a Google Cloud certification demonstrates your cloud knowledge to employers and validates your understanding of Google Cloud products and solutions. The skill set for each role-based certification is assessed using thorough industry-standard methods, and your achievement is recognized by passing a certification exam. Google Cloud certifications are among the highest paying IT certifications, and 87% of users feel more confident in their cloud skills when they are #GoogleCloudCertified.
Google Cloud certifications are offered for three levels: foundational (no-hands on experience required), associate (6+ months recommended of building on Google Cloud), and professional (3+ years of industry experience and 1+ year using Google Cloud recommended). They span roles like cloud architect, cloud engineer, and data engineer. Explore the full portfolio to find out which certification is right for you.
You’ll start working towards certification by utilizing training resources to help you prepare for the certification exam, and getting hands-on experience where indicated. Some certifications also offer a no-cost course to help you in preparing you for the exam: learn about the domains covered in the exam, assess your exam readiness, and create a study plan. No-cost exam guides and sample questions are also available for all the certification exams. Here are the courses to learn more:
Another way to work towards certification is by checking out ‘Level up your cloud career with Google Cloud credentials and certifications’ on Innovators Live. We talked with Google Cloud Champion Innovators, who offer tips for the certification journey and share how they’ve approached their learning journey. Watch here.
Microsoft Teams is introducing Recording and Transcript APIs to enhance the meeting experience and provide valuable insights for developers and users.
Developers can use these APIs to quickly generate meeting summaries, including key points, action items, and questions, and even capture meeting highlights. This feature can ensure that important information from meetings is not lost and can be easily referenced later.
These APIs can help you understand how people in a meeting feel and how engaged they are. It’s like understanding whether they are happy, excited, or bored during the conversation. This information can help determine how well the meeting is going and how people react to the discussion.
By analyzing previous meeting content, these APIs enable the generation of insights for follow-up actions. For example, in a sales context, the API could suggest what topics or strategies to discuss in the next sales call based on the outcomes of previous meetings. In the case of interviews, it can provide insights for improving the interview process.
The pricing for the Microsoft Teams Recording and Transcript APIs, as of September 1, 2023, is as follows:
Recording API: This API is priced at $0.03 per minute. This pricing applies to fetching and managing meeting recordings programmatically using the API.
Transcription API: The Transcription API is priced at $0.024 per minute. Transcription involves converting spoken words in the meeting into text, making it searchable and accessible.
The pricing seems to be reasonable. These features ultimately aim to make meetings more productive by automating tasks like note-taking and action item tracking, allowing users to focus on collaboration and problem-solving.
Mountpoint for Amazon S3 is an open source file client that makes it easy for your file-aware Linux applications to connect directly to Amazon Simple Storage Service (Amazon S3) buckets. Announced earlier this year as an alpha release, it is now generally available and ready for production use on your large-scale read-heavy applications: data lakes, machine learning training, image rendering, autonomous vehicle simulation, ETL, and more. It supports file-based workloads that perform sequential and random reads, sequential (append only) writes, and that don’t need full POSIX semantics.
Why Files? Many AWS customers use the S3 APIs and the AWS SDKs to build applications that can list, access, and process the contents of an S3 bucket. However, many customers have existing applications, commands, tools, and workflows that know how to access files in UNIX style: reading directories, opening & reading existing files, and creating & writing new ones. These customers have asked us for an official, enterprise-ready client that supports performant access to S3 at scale. After speaking with these customers and asking lots of questions, we learned that performance and stability were their primary concerns, and that POSIX compliance was not a necessity.
When I first wrote about Amazon S3 back in 2006 I was very clear that it was intended to be used as an object store, not as a file system. While you would not want use the Mountpoint / S3 combo to store your Git repositories or the like, using it in conjunction with tools that can read and write files, while taking advantage of S3’s scale and durability, makes sense in many situations.
All About Mountpoint Mountpoint is conceptually very simple. You create a mount point and mount an Amazon S3 bucket (or a path within a bucket) at the mount point, and then access the bucket using shell commands (ls, cat, dd, find, and so forth), library functions (open, close, read, write, creat, opendir, and so forth) or equivalent commands and functions as supported in the tools and languages that you already use.
Under the covers, the Linux Virtual Filesystem (VFS) translates these operations into calls to Mountpoint, which in turns translates them into calls to S3: LIST, GET, PUT, and so forth. Mountpoint strives to make good use of network bandwidth, increasing throughput and allowing you to reduce your compute costs by getting more work done in less time.
Installing and UsingMountpoint for Amazon S3 Mountpoint is available in RPM format and can easily be installed on an EC2 instance running Amazon Linux. I simply fetch the RPM and install it using yum:
For the last couple of years I have been regularly fetching images from several of the Washington State Ferry webcams and storing them in my wsdot-ferry bucket:
I collect these images in order to track the comings and goings of the ferries, with a goal of analyzing them at some point to find the best times to ride. My goal today is to create a movie that combines an entire day’s worth of images into a nice time lapse. I start by creating a mount point and mounting the bucket:
I can traverse the mount point and inspect the bucket:
$ cd wsdot-ferry
$ ls -l | head -10
total 0
drwxr-xr-x 2 jeff jeff 0 Aug 7 23:07 2020_12_30
drwxr-xr-x 2 jeff jeff 0 Aug 7 23:07 2020_12_31
drwxr-xr-x 2 jeff jeff 0 Aug 7 23:07 2021_01_01
drwxr-xr-x 2 jeff jeff 0 Aug 7 23:07 2021_01_02
drwxr-xr-x 2 jeff jeff 0 Aug 7 23:07 2021_01_03
drwxr-xr-x 2 jeff jeff 0 Aug 7 23:07 2021_01_04
drwxr-xr-x 2 jeff jeff 0 Aug 7 23:07 2021_01_05
drwxr-xr-x 2 jeff jeff 0 Aug 7 23:07 2021_01_06
drwxr-xr-x 2 jeff jeff 0 Aug 7 23:07 2021_01_07
$
$ cd 2020_12_30
$ ls -l
total 0
drwxr-xr-x 2 jeff jeff 0 Aug 7 23:07 fauntleroy_holding
drwxr-xr-x 2 jeff jeff 0 Aug 7 23:07 fauntleroy_way
drwxr-xr-x 2 jeff jeff 0 Aug 7 23:07 lincoln
drwxr-xr-x 2 jeff jeff 0 Aug 7 23:07 trenton
drwxr-xr-x 2 jeff jeff 0 Aug 7 23:07 vashon_112_north
drwxr-xr-x 2 jeff jeff 0 Aug 7 23:07 vashon_112_south
drwxr-xr-x 2 jeff jeff 0 Aug 7 23:07 vashon_bunker_north
drwxr-xr-x 2 jeff jeff 0 Aug 7 23:07 vashon_bunker_south
drwxr-xr-x 2 jeff jeff 0 Aug 7 23:07 vashon_holding
$
$ cd fauntleroy_holding
$ ls -l | head -10
total 2680
-rw-r--r-- 1 jeff jeff 19337 Feb 10 2021 17-12-01.jpg
-rw-r--r-- 1 jeff jeff 19380 Feb 10 2021 17-15-01.jpg
-rw-r--r-- 1 jeff jeff 19080 Feb 10 2021 17-18-01.jpg
-rw-r--r-- 1 jeff jeff 17700 Feb 10 2021 17-21-01.jpg
-rw-r--r-- 1 jeff jeff 17016 Feb 10 2021 17-24-01.jpg
-rw-r--r-- 1 jeff jeff 16638 Feb 10 2021 17-27-01.jpg
-rw-r--r-- 1 jeff jeff 16713 Feb 10 2021 17-30-01.jpg
-rw-r--r-- 1 jeff jeff 16647 Feb 10 2021 17-33-02.jpg
-rw-r--r-- 1 jeff jeff 16750 Feb 10 2021 17-36-01.jpg
$
As you can see, I used Mountpoint to access the existing image files and to write the newly created animation back to S3. While this is a fairly simple demo, it does show how you can use your existing tools and skills to process objects in an S3 bucket. Given that I have collected several million images over the years, being able to process them without explicitly syncing them to my local file system is a big win.
Mountpoint for Amazon S3 Facts Here are a couple of things to keep in mind when using Mountpoint:
Pricing – There are no new charges for the use of Mountpoint; you pay only for the underlying S3 operations. You can also use Mountpoint to access requester-pays buckets.
Performance – Mountpoint is able to take advantage of the elastic throughput offered by S3, including data transfer at up to 100 Gb/second between each EC2 instance and S3.
Credentials – Mountpoint accesses your S3 buckets using the AWS credentials that are in effect when you mount the bucket. See the CONFIGURATION doc for more information on credentials, bucket configuration, use of requester pays, some tips for the use of S3 Object Lambda, and more.
Operations& Semantics – Mountpoint supports basic file operations, and can read files up to 5 TB in size. It can list and read existing files, and it can create new ones. It cannot modify existing files or delete directories, and it does not support symbolic links or file locking (if you need POSIX semantics, take a look at Amazon FSx for Lustre). For more information about the supported operations and their interpretation, read the SEMANTICS document.
Storage Classes – You can use Mountpoint to access S3 objects in all storage classes except S3 Glacier Flexible Retrieval, S3 Glacier Deep Archive, S3 Intelligent-Tiering Archive Access Tier, and S3 Intelligent-Tiering Deep Archive Access Tier.
Open Source – Mountpoint is open source and has a public roadmap. Your contributions are welcome; be sure to read our Contributing Guidelines and our Code of Conduct first.
Hop On As you can see, Mountpoint is really cool and I am guessing that you are going to find some awesome ways to put it to use in your applications. Check it out and let me know what you think!
In a move that promises to simplify the way we use computers, Microsoft has unveiled a new feature in conjunction with its Windows 365 service – the Windows 365 Switch. This innovative feature is now available for public preview today.
Introducing Windows 365 Switch
Windows 365 Switch offers fluid transitions between a Windows 365 Cloud PC and the local desktop. It utilizes the same keyboard commands that users are accustomed to, and the transition can be done with a simple mouse click or swipe gesture.
Advantages for BYOD Users
This marks a significant advantage for those in BYOD (bring your device) scenarios. The ability to easily switch from a personal device to a secure, company-owned cloud PC offers flexibility, security, and peace of mind. It eliminates the fear of a lost or stolen device compromising company data.
Prerequisites for Windows 365 Switch
Microsoft has laid out specific criteria for utilizing the Windows 365 Switch:
A Windows 11-based endpoint (Windows 11 Pro and Enterprise are currently supported)
Enrollment in the Windows Insider Program (Beta Channel)
A Windows 365 Cloud PC license
Once these prerequisites are met, users can download the Windows 365 App, version 1.3.177.0 or newer, from the Microsoft Store. For convenience, IT admins can deploy the app for end users via Microsoft Intune.
The Switch Experience
After installing the Windows 365 App, users can expect a short wait, typically a few hours, for the switch feature to become fully enabled. Subsequently, the switch can be invoked either via the Task View feature adjacent to the Search button on the Windows 11 taskbar or via the Windows 365 app.
This significant step in the evolution of desktop computing brings the industry closer to a reality where the boundaries between local and cloud computing become blurred. As we eagerly anticipate what more Microsoft has in store for Windows 365, the imminent official release of the Windows 365 Switch is a clear leap in that direction.
Microsoft has released a new zoom controls feature in preview for Microsoft Teams. This update allows participants to zoom in and out while viewing content on a shared screen in Teams meetings and calls.
Up until now, Microsoft Teams only allowed meeting attendees to use pinch to zoom gesture on trackpads or other shortcuts to view content such as Excel Spreadsheets or PowerPoint presentations. The new zoom controls should be a welcome addition for people with low vision or visual impairment.
“Users in a Teams call or meeting will now see new buttons to zoom in, zoom out and restore the original size of the incoming screen share. This will greatly enhance the experience of users viewing screen share,” the Office Insider team explained.
To try out zoom controls, IT admins will have to sign up for the Microsoft Teams public preview program. They will need to configure an update policy in the Microsoft Teams admin center. However, keep in mind that meeting participants will not be able to view zoom controls while using the watermarking feature during Teams meetings.
Microsoft Teams zoom controls available for desktop and web users
As of this writing, the feature is only available in the Microsoft Teams app for Windows, macOS, and web app. It remains to be seen if Microsoft plans to add zoom controls to the Teams mobile clients.
In related news, Microsoft is getting ready to make the new Teams 2.0 client the default experience on Windows later this year. Last week, Microsoft Product Lead for Teams 2.0 Anupam Pattnaik confirmed in the first episode of Petri’s UnplugIT podcast that the app is also coming in preview to macOS, the web, and other platforms later this year.
Microsoft Teams 2.0 debuted in public preview on Windows back in March 2023. The app has been rebuilt from the ground up to improve performance and reduce power consumption on Windows devices.
Firewalls are a critical component of your security architecture. With the increased migration of workloads to cloud environments, more companies are turning to cloud-first solutions for their network security needs.
Google Cloud Firewall is a scalable, cloud-first service with advanced protection capabilities that helps enhance and simplify your network security posture. Google Cloud Firewall’s fully distributed architecture automatically applies pervasive policy coverage to workloads wherever they are deployed in Google Cloud. Stateful inspection enforcement of firewall policies occurs at each virtual machine (VM) instance.
Cloud Firewall offers the following benefits:
Built-in scalability: With Cloud Firewall, the firewall policy accompanies each workload as part of the forwarding fabric, which enables the service to scale intrinsically. This can relieve customers of the operational burden to spend time and resources to help ensure scalability.
Availability: Cloud Firewall policies automatically apply to workloads wherever they are instantiated in the Google Cloud environment. The fully distributed architecture can allow for precise rule enforcement, even down to a single VM interface.
Simplified management: Cloud Firewall security policies for each workload are independent of the network architecture, subnets and routing configuration. The context-aware and dynamically updating objects for firewall rules enable simplified configuration, deployment and ongoing maintenance.
How to migrate from on-prem to Cloud Firewall
Most on-premises firewall appliances, either virtual or physical, are deployed in one of two modes:
Zone-based that creates trusted and untrusted zones to apply firewall policies; or
Access Control Lists (ACL) applied to an interface.
In both cases, the firewall’s primary purpose is to protect one perimeter or network segment from another. For example, you may use a zone based firewall to filter traffic from an “untrusted” to a “trusted” zone. Similarly, you may have an ACL-based firewall to protect an “inside” network segment from an “outside” network segment.
However, that strategy is not the best approach with Google Cloud Firewall policies and rules. Cloud Firewall is not designed to act as a perimeter device; rather, Cloud Firewall is a fully distributed set of rules to help protect individual resources, such as VMs. However, most of our customers want to replicate their on-prem firewall logic and apply it to their cloud environment. Take the following example:
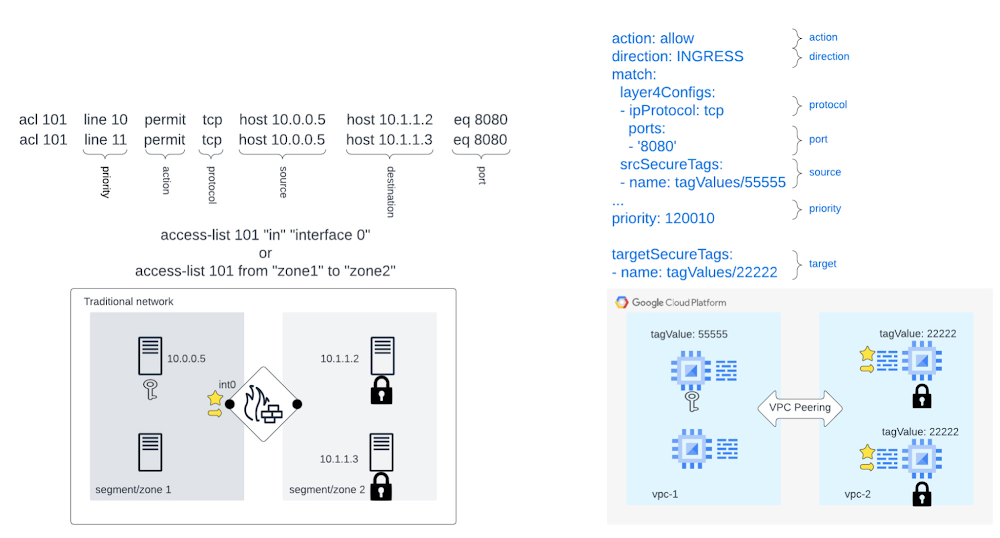
Example: Firewall rule that allows “key” to access “lock” on port 8080
There are a lot of similar components shared between on-prem firewall appliance rules and Cloud Firewall rules. However, some critical differences between them can make a migration from firewall appliances to Cloud Firewalls a challenging task, for example:
Traditional firewalls protect a perimeter. In Google Cloud, firewall rules protect resources. This is done through the concept of “targets,” which specify which resources a given firewall rule applies to.
There are multiple types of firewall options available in Google Cloud (hierarchical firewall policies, global/regional firewall policies, and Virtual Private Cloud (VPC) firewall rules). Deciding which type of rules to use, and how to configure the rules with your cloud network architecture requires review and planning.
Furthermore, there are some additional firewall rules that may be needed in a cloud environment when compared to an on-prem firewall. For example, you may need to create ingress firewall rules to allow Google Cloud health check traffic to load balancer backends or you may need to create an egress rule to allow VMs access to use the Google Cloud APIs. Further, on-prem firewalls often have additional functions in on-prem networks including routing, NATing, VPN termination, and in some cases, Layer 7 inspection.
To assist customers with the migration from on-prem firewall appliances to Cloud services, including Cloud Firewall, we have developed a best practice guide that includes design and architecture considerations, and a side-by-side comparison of on-prem to Cloud Firewall rules. Check out the guide here for more information.
In this article, I’ll explain how to use the PowerShell Where-Object cmdlet to filter objects and data. I’ll provide a series of easy examples showing you how to filter files by name or date, how to filter processes by status or CPU usage, and more.
When using PowerShell, you will often receive an extremely large amount of data when querying your environment. For example, If you run the Get-AzureADUser cmdlet against an Azure Active Directory database with 100,000 users, you will get…well, 100,000 results. That may take some time to output to your console!
Normally you won’t need to get all that information. The Where-Object cmdlet is an extremely helpful tool that will allow you to filter your results to pinpoint exactly the information you’re looking for.
What is the PowerShell Where-Object command?
PowerShell Where-Object is by far the most often-used tool for filtering data. Mostly due to its power and, at the same time, simplicity. It selects objects from a collection based on their property values.
There are other cmdlets that allow you to filter data. The Select-Object cmdlet selects objects (!) or object properties. Select-String finds text in strings and files. They both are valuable and have their niche in your tool belt.
Here are some brief examples for you. Select-Object commands help in pinpointing specific pieces of information. This example returns objects that have the Name, ID, and working set (WS) properties of process objects.
How to filter an array of objects with PowerShell Where-Object
The task at hand is filtering a large pool of data into something more manageable. Thankfully, there are several methods we have to filter said data. Starting with PowerShell version 3.0, we can use script blocks and comparison operators, the latter being the more recent addition and the ‘preferred’ method.
With the Where-Object cmdlet, you’re constructing a condition that returns True or False. Depending on the result, it returns the pertinent output, or not.
Building filters with script blocks
Using script blocks in PowerShell goes back to the beginning. These components are used in countless places. Script blocks allow you to separate code via a filter and execute it in various places.
To use a script block as a filter, you use the FilterScript parameter. I’ll show you an example shortly. If the script block returns a value other than False (or null), it will be considered True. If not, False.
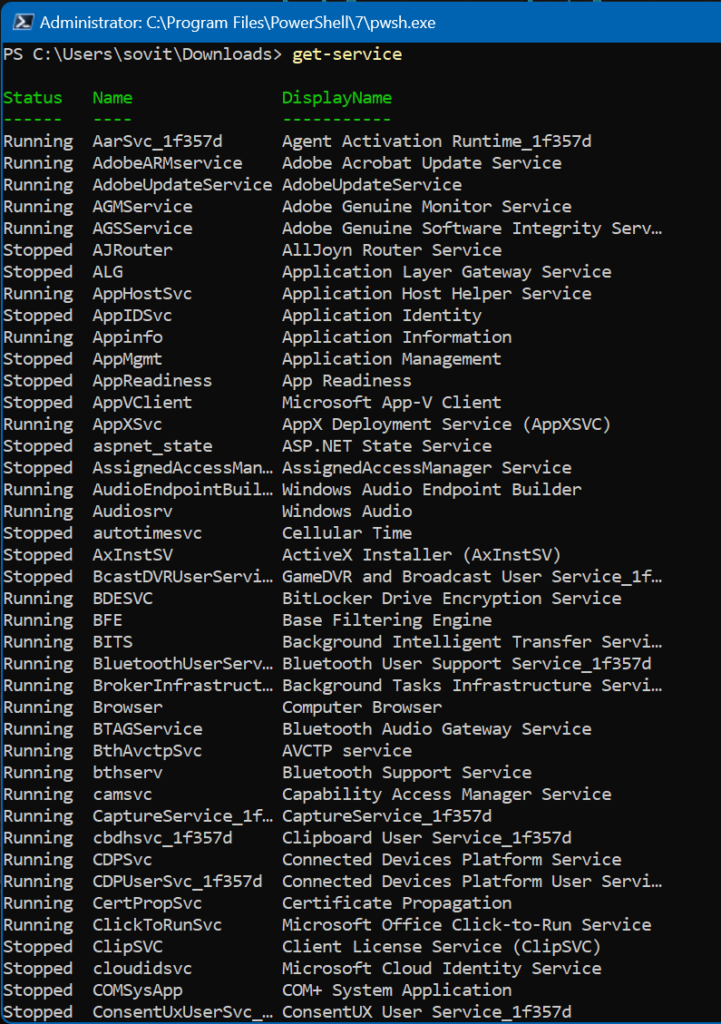
Let’s show this via an example: You have been assigned a task from your manager to determine all the services on a computer that are set to Disabled.
We will first gather all the services with Get-Service cmdlet. This pulls all the attributes of all the services on the computer in question. Using the PowerShell pipeline, we can then ‘pipe’ the gathered results using the FilterScript parameter. We can use this example below to find all the services set to Disabled.
($_.StartType -EQ 'Disabled')
First off, if we just use the Get-Service cmdlet, we get the full list of services. And there were quite a few more screens of services beyond the image below.
There are a LOT of services on Windows 11…
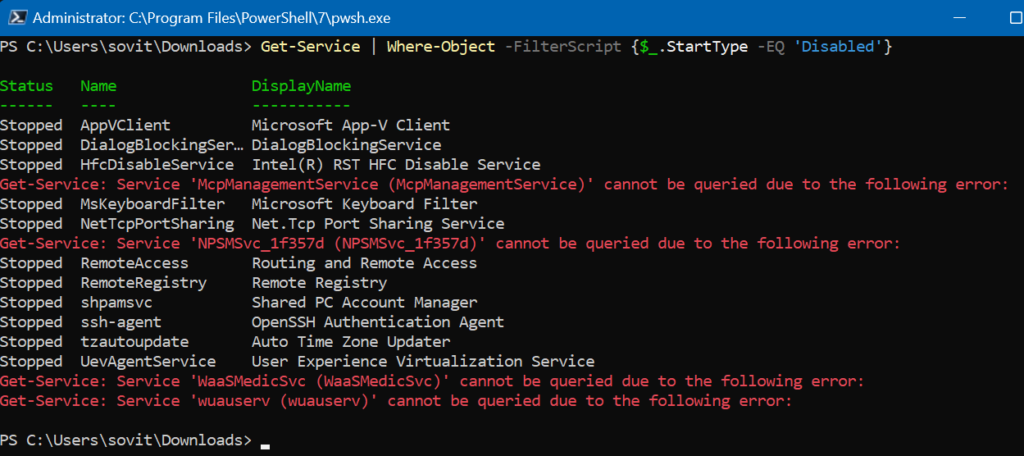
Not exactly what we’re looking for. Once we have the script block, we pass it right on to the FilterScript parameter.
We can see this all come to fruition with this example. We are using the Get-Service cmdlet to gather all the disabled services on our computer.
There we go. Now, we have the 15 services that are set to Disabled, satisfying our request.
Filtering objects with comparison operators
The issue with the prior method is it makes the code more difficult to understand. It’s not the easiest syntax for beginners to get ramped up with PowerShell. Because of this ‘learning curve’ issue, the engineers behind PowerShell produced comparison statements.
These have more of a flow with them. We can produce some more elegant, efficient, and ‘easier-to-read’ code using our prior example.
See? A little more elegant and easier to read. Using the Property parameter and the eq operator as a parameter allows us to also pass the value of Disabled to it. This eliminates our need to use the script block completely!
Containment operators
Containment operators are useful when working with collections. These allow you to define a condition. There are several examples of containment operators we can use. Here are a few:
-contains – Filter a collection containing a property value.
-notcontains – Filter a collection that does not contain a property value.
-in – Value is in a collection, returns property value if a match is found.
For case sensitivity, you can append ‘c’ at the beginning of the commands. For example, ‘-ccontains’ is the case-sensitive command for filtering a collection containing a property value.
Equality operators
There are a good number of equality operators. Here are a few:
-eq / -ceq – Value equal to specified value / case-sensitive option.
-le – value less than or equal to specified value.
Matching operators
We also have matching operators to use. These allow you to match strings inside of other strings, so that ‘Windows World Wide’ -like ‘World*’ returns a True output.
You use these just like when using containment operators.
Can you use multiple filter conditions with both methods?
Come to think of it, yes, you certainly can use both methods in your scripts. Even though comparison operators are more modern, there are times when working with more complex filtering requirements will dictate you to use script blocks. You’ll be able to find the balance yourself as you learn and become more proficient with your scripts.
Filtering with PowerShell Where-Object: Easy Examples
Let’s go through some simple examples of using the Where-Object cmdlet to determine pieces of information. Eventually, we’ll be able to accomplish tasks with ease.
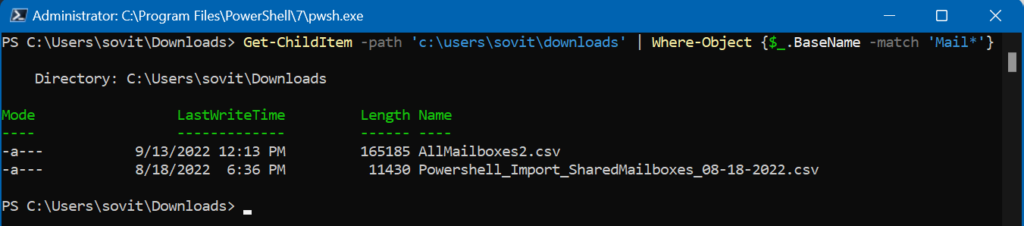
Filtering files by name
We can certainly filter a directory of files that match specific criteria. We can use the Get-ChildItem cmdlet to first gather the list of files in my Downloads folder. Then, I use the Where-Object cmdlet with the ‘BaseName‘ parameter to find all files that have ‘Mail’ in the filenames.
We can use also wildcard characters here. Let’s give it a whirl:
Filtering files in a folder matching a specific filename wildcard.
Piece of cake. So, imagine a scenario where you have a folder with 25,000 files in it, and all the filenames are just strings of alphanumeric characters. Being able to quickly find the file(s) with an exact character match is ideal and a HUGEtimesaver!
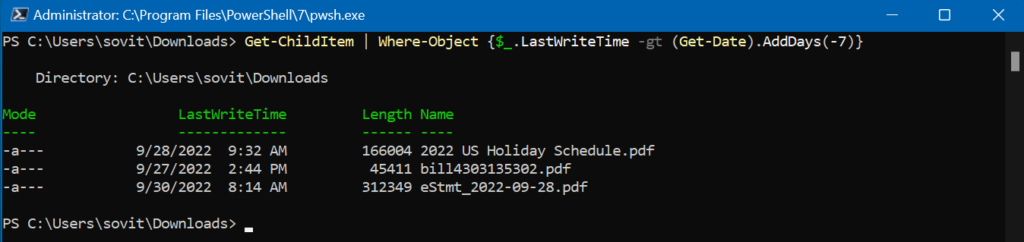
Filtering files by date
We can use the same commands, Get-ChildItem and Where-Object, to find files based on dates, too. Let’s say we want to find all files that were created or updated in the last week. Let’s do this!
Filtering files in a directory by last saved time – wonderful tool!
We are using the LastWriteTime property and the Get-Date and AddDays parameters to make this work. It works wonderfully.
Filtering processes by name
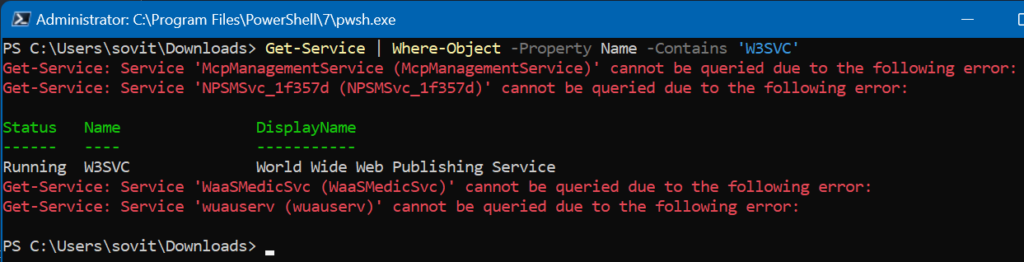
Because it is SO much fun working with Windows Services, let’s continue in this lovely realm. We are trying to determine the name of the ‘WWW’ service. We can use the ‘Property‘ parameter again.
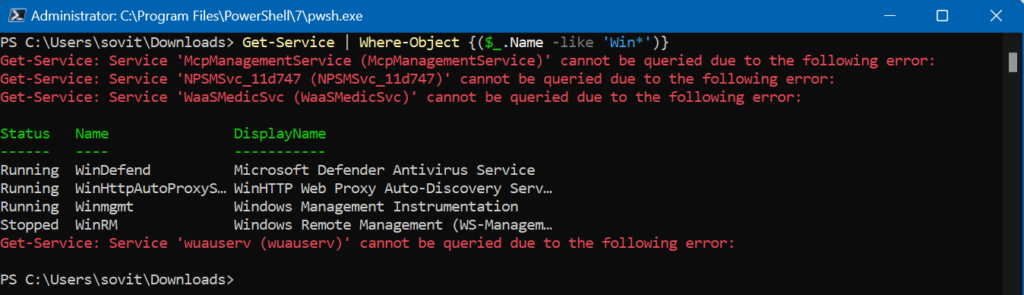
Get-Service | Where-Object -Property Name -Contains 'W3SVC'
Locating the WWW Publishing Service
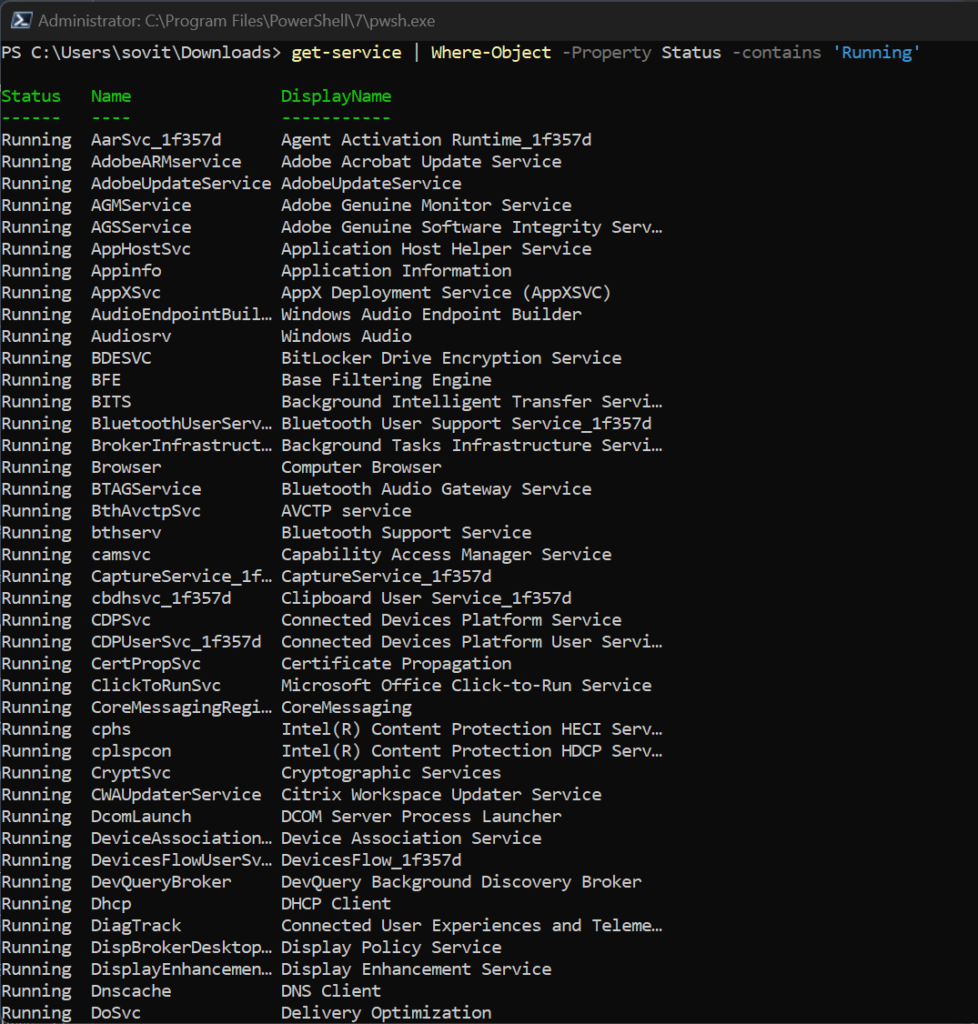
Filtering processes by status
There are several properties with each service, so we can also use a containment operator to gather a list of all services that are in a Running state.
Get-Service | Where-Object -Property Status -Contains 'Running'
Listing all Running Services
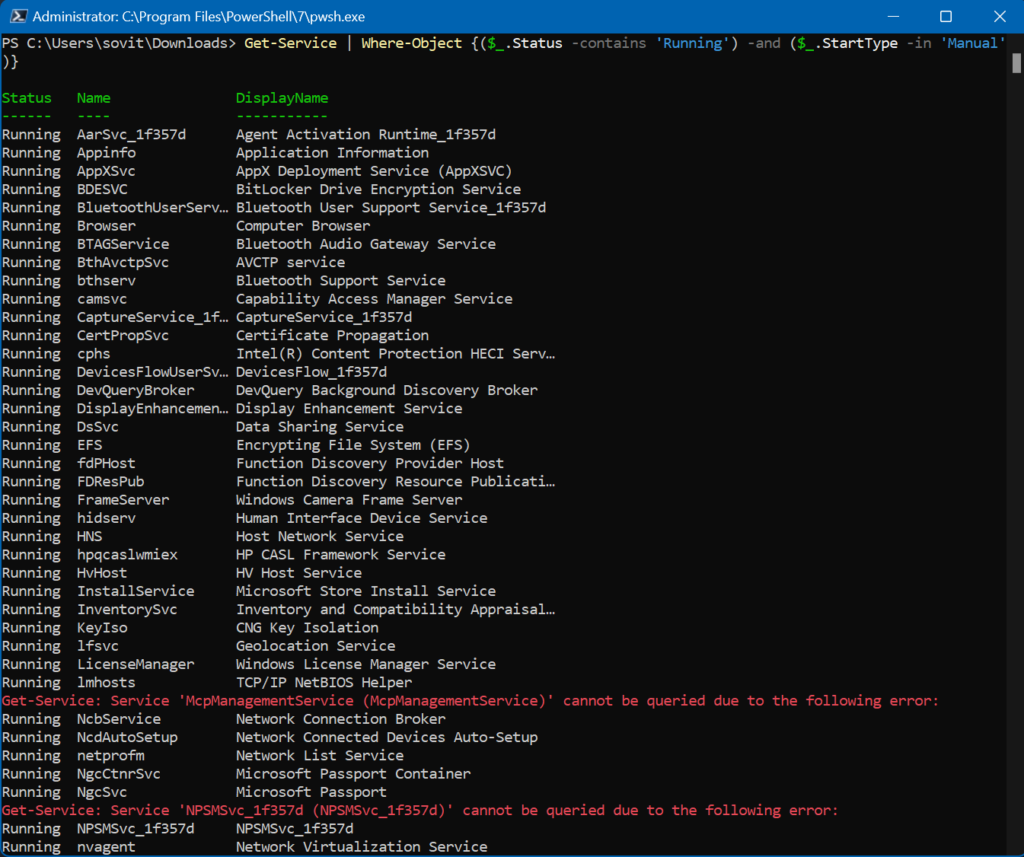
Filtering processes by name and status
Remember what I said about script blocks? Let’s use one here to accomplish to filter processes by name and status. We will get all the services that are running but also have a StartType parameter set to Manual. Here we go!
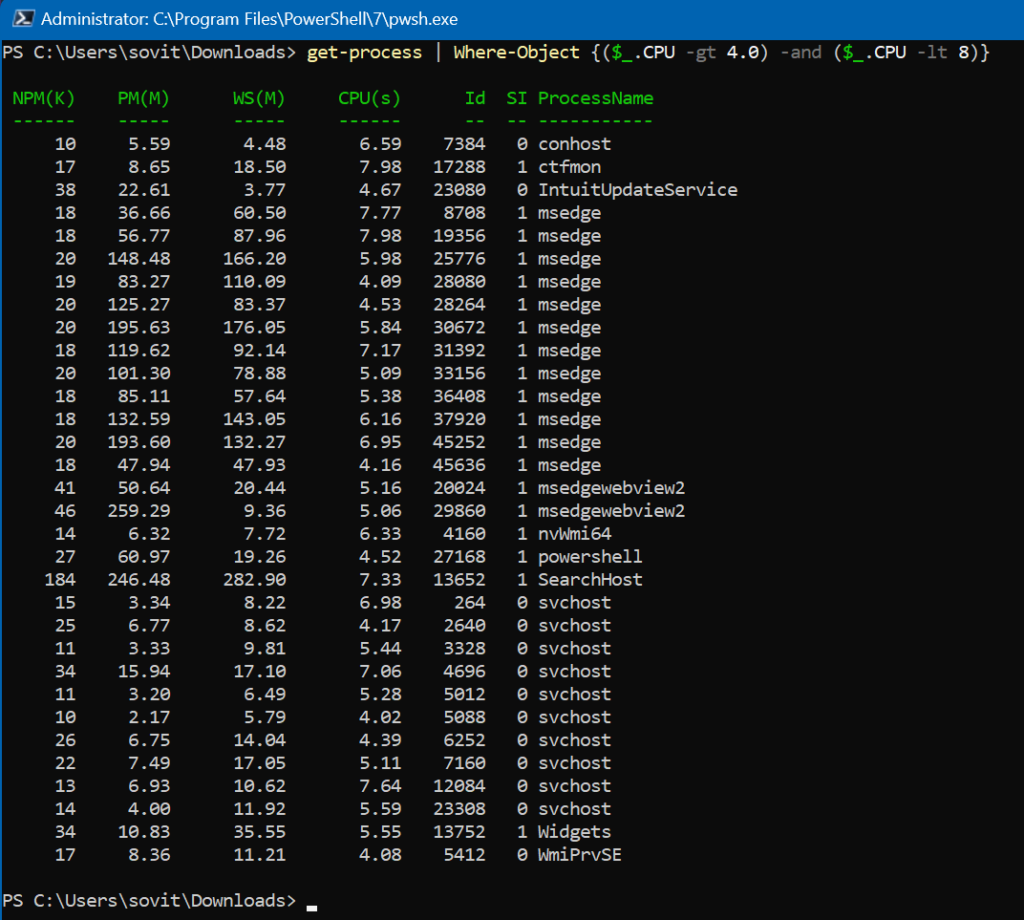
You can also use equality operators with Where-Object to compare values. Here, we’ll use an operator and the Get-Process command to filter all running processes on our computer based on CPU usage.
Let’s use a script block to find all processes that are using between 4 and 8 percent of the CPU.
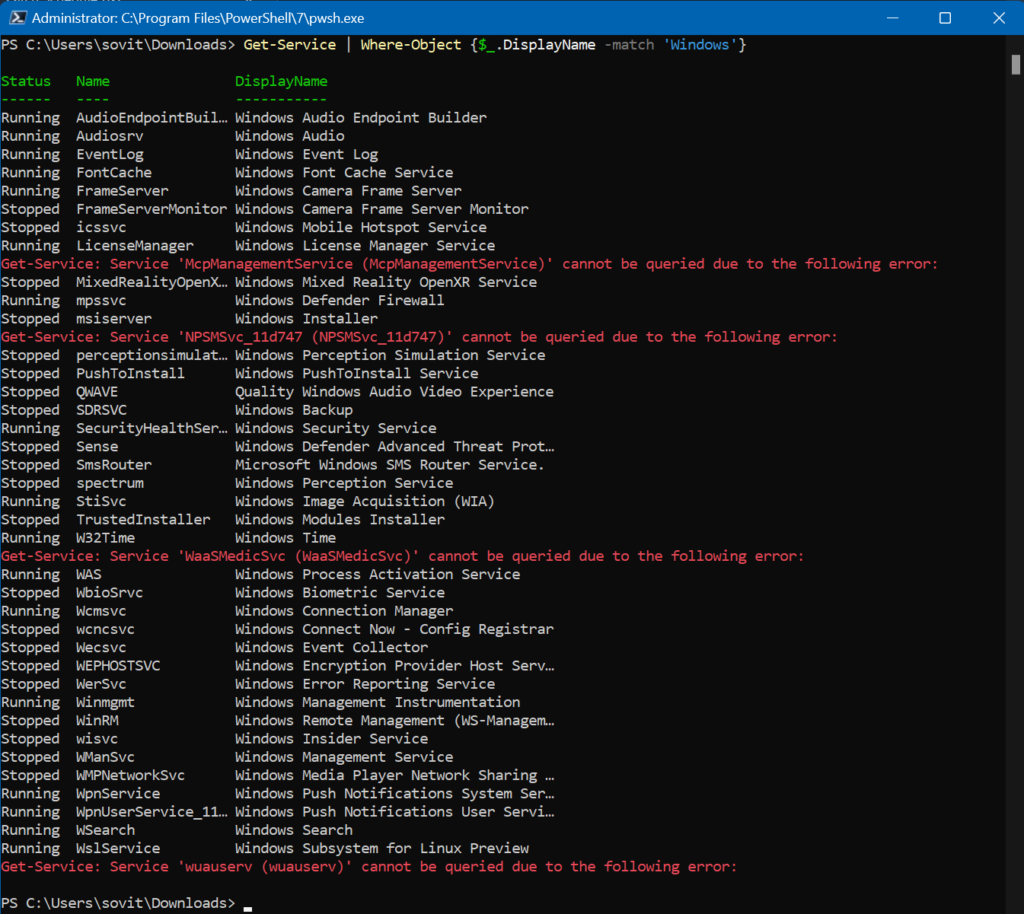
All the Services that have ‘Win’ starting their Name parameter
Finding PowerShell commands with a specific name
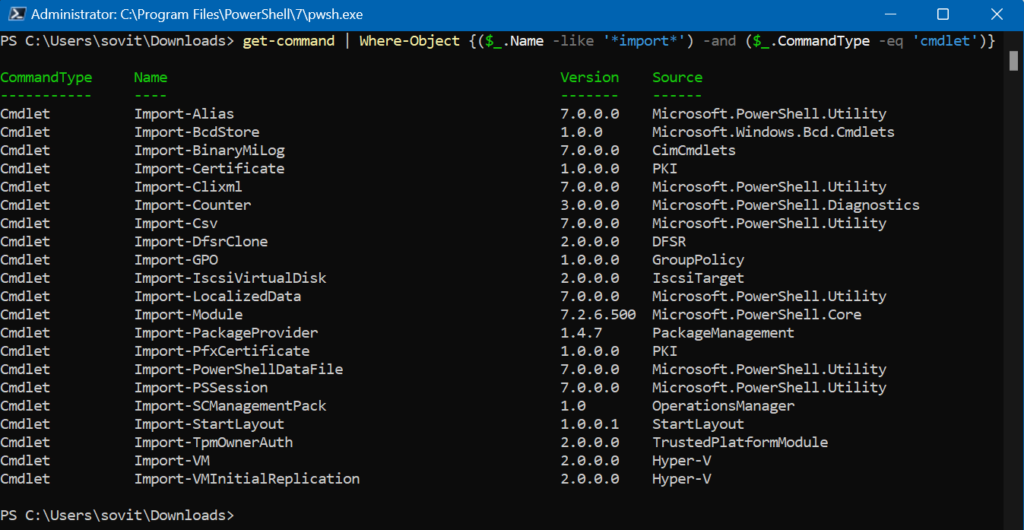
Our cmdlet also lets you use logical operators to link together multiple expressions. You can evaluate multiple conditions in one script block. Here are some examples.
-and – The script block evaluates True if the expressions are both logically evaluated as True
-or – The block evaluates to True when one of the expressions on either side are True
-xor – The script block evaluates to True when one of the expressions is True and the other is False.
-not or ‘!’ – Negates the script element following it.
Let me show you an example that illustrates this concept.
Showing all the commands locally that have ‘Import’ in their name and are PowerShell cmdlets
Very useful!
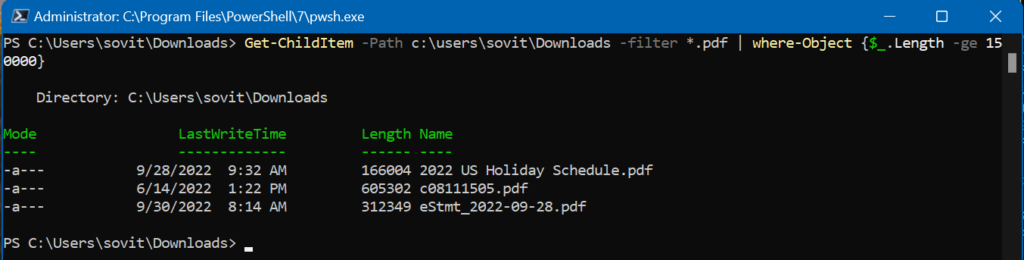
Finding files of a specific type with a specific size
You’ve already seen a few examples of the ‘-filter‘ command above. This is the main example of using filter parameters in your commands and scripts. It lets you home in on the precise data you’re looking for. Let me show you an example.
This command filters out all the files in the folder for PDF files. It then pipes that to the Where-Object cmdlet, which will further narrow the list down to PDF files that are 150K or larger. Very useful!
Conclusion
The ‘Where-Object’ cmdlet is very powerful in helping you quickly pinpoint exactly the data points you are looking for. Being able to check all Services that are set to Automatic yet are not Running can be extremely helpful during troubleshooting episodes. And using it to find errant, high-CPU processes in a programmatic way can also help you with scripting these types of needs.
If you have any comments or questions, please let me know down below. Thank you for reading!
We recently released our largest update to Chocolatey Central Management so far. Join Gary to find out more about Chocolatey Central Management and the new features and fixes we’ve added to this release.
Chocolatey Central Management provides real-time insights, and deployments of both Chocolatey packages and PowerShell code, to your client and server devices.
Industry after industry being transformed by software. It started with industries such as music, film and finance, whose assets lent themselves to being easily digitized. Fast forward to today, and we see a push to transform industries that have more physical hardware and require more human interaction, for example healthcare, agriculture and freight. It’s harder to digitize these industries – but it’s arguably more important. At Einride, we’re doing just that.
Our mission is to make Earth a better place through intelligent movement, building a global autonomous and electric freight network that has zero dependence on fossil fuel. A big part of this is Einride Saga, the software platform that we’ve built on Google Cloud. But transforming the freight industry is a formidable technical task that goes far beyond software. Still, observing the software transformations of other industries has shown us a powerful way forward.
So, what lessons have we learned from observing the industries that led the charge?
The Einride Pod, an autonomous, all-electric freight vehicle designed and developed by Einride – here shown in pilot operations at GEA Appliance Park in Louisville, KY.
Lessons from re-architecting software systems
Most of today’s successful software platforms started in co-located data centers, eventually moving into the public cloud, where engineers could focus more on product and less on compute infrastructure. Shifting to the cloud was done using a lift-and-shift approach: one-to-one replacements of machines in datacenters with VMs in the cloud. This way, the systems didn’t require re-architecting, but it was also incredibly inefficient and wasteful. Applications running on dedicated VMs often had, at best, 20% utilization. The other 80% was wasted energy and resources. Since then, we’ve learned that there are better ways to do it.
Just as the advent of shipping containers opened up the entire planet for trade by simplifying and standardizing shipping cargo, containers have simplified and standardized shipping software. With containers, we can leave management of VMs to container orchestration systems like Kubernetes, an incredibly powerful tool that can manage any containerized application. But that power comes at the cost of complexity, often requiring dedicated infrastructure teams to manage clusters and reduce cognitive load for developers. That is a barrier of entry to new tech companies starting up in new industries — and that is where serverless comes in. Serverless offerings like Cloud Run abstract away cluster management and make building scalable systems simple for startups and established tech companies alike.
Serverless isn’t a fit for all applications, of course. While almost any application can be containerized, not all applications can make use of serverless. It’s an architecture paradigm that must be considered from the start. Chances are, an application designed with a VM-focused mindset won’t be fully stateless, and this prevents it from successfully running on a serverless platform. Adopting a serverless paradigm for an existing system can be challenging and will often require redesign.
Even so, the lessons from industries that digitized early are many: by abstracting away resource management, we can achieve higher utilization and more efficient systems. When resource management is centralized, we can apply algorithms like bin packing, and we can ensure that our workloads are efficiently allocated and dynamically re-allocated to keep our systems running optimally. With centralization comes added complexity, and the serveless paradigm enables us to shift complexity away from developers, as well as from entire companies.
Opportunities in re-architecting freight systems
At Einride, we have taken the lessons from software architecture and applied them to how we architect our freight systems. For example, the now familiar “lift-and-shift” approach is frequently applied in the industry for the deployment of electric trucks – but attempts at one-to-one replacements of diesel trucks lead to massive underutilization.
With our software platform, Einride Saga, we address underutilization by applying serverless patterns to freight, abstracting away complexity from end-customers and centralizing management of resources using algorithms. With this approach, we have been able to achieve near-optimal utilization of the electric trucks, chargers and trailers that we manage.
But to get these benefits, transport networks need to be re-architected. Flows in the network need to be reworked to support electric hardware and more dynamic planning, meaning that shippers will need to focus more on specifying demand and constraints, and less on planning out each shipment by themselves.
We have also found patterns in the freight industry that influence how we build our software. Managing electric trucks has made us aware of the differences in availability of clean energy across the globe, because – much like electric trucks – Einride Saga relies on clean energy to operate in a sustainable way. With Google Cloud, we can run the platform on renewable energy, worldwide.
The core concepts of serverless architecture — raising the abstraction level, and centralizing resource management — have the potential to revolutionize the freight industry. Einride’s success has sprung from an ability to realize ideas and then quickly bring them to market. Speed is everything, and the Saga platform – created without legacy in Google Cloud – has enabled us to design from the ground up and leverage the benefits of serverless.
Advantages of a serverless architecture
Einride’s architecture supports a company that combines multiple groundbreaking technologies — digital, electric and autonomous — into a transformational end-to-end freight service. The company culture is built on transparency and inclusivity, with digital communication and collaboration enabled by the Google Workspace suite. The technology culture promotes shared mastery of a few strategically selected technologies, enabling developers to move seamlessly up and down the tech stack — from autonomous vehicle to cloud platform.
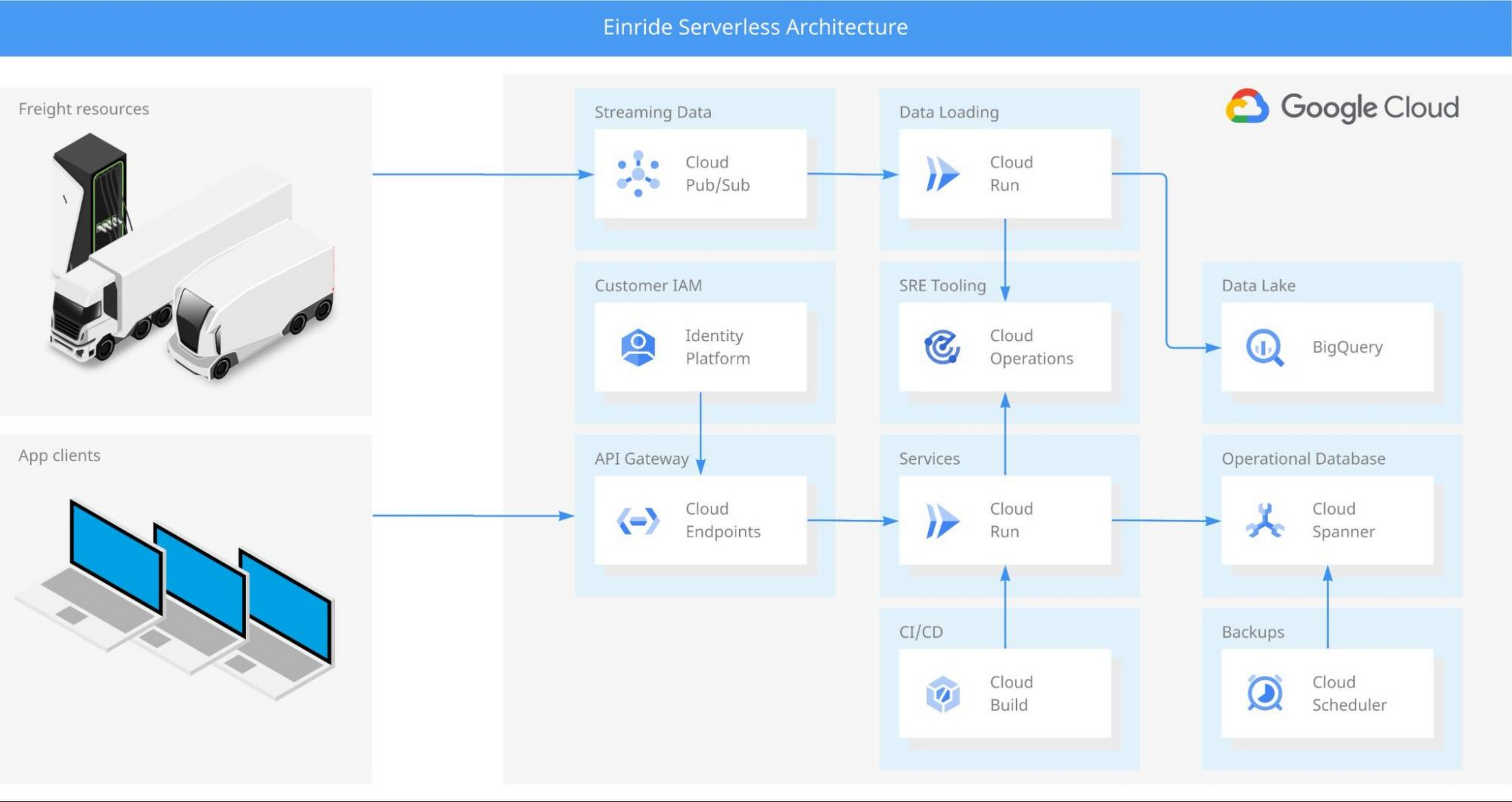
If a modern autonomous vehicle is a data center on wheels, then Go and gRPC are fuels that make our vehicle services and cloud services run. We initially started building our cloud services in GKE, but when Google Cloud announced gRPC support for Cloud Run (in September 2019), we immediately saw the potential to simplify our deployment setup, spend less time on cluster management, and increase the scalability of our services. At the time, we were still very much in startup mode, making Cloud Run’s lower operating costs a welcome bonus. When we migrated from GKE to Cloud Run and shut down our Kubernetes clusters, we even got a phone call from our reseller who noticed that our total spend had dropped dramatically. That’s when we knew we had stumbled on game-changing technology!
Einride serverless architecture showing a gRPC-based microservice platform, built on Cloud Run and the full suite of Google Cloud serverless products
In Identity Platform, we found the building blocks we needed for our Customer Identity and Access Management system. The seamless integration with Cloud Endpoints and ESPv2 enabled us to deploy serverless API gateways that took care of end-user authentication and provided transcoding from HTTP to gRPC. This enabled us to get the performance and security benefits of using gRPC in our backends, while keeping things simple with a standard HTTP stack in our frontends.
For CI/CD, we adopted Cloud Build, which gave all our developers access to powerful build infrastructure without having to maintain our own build servers. With Go as our language for backend services, ko was an obvious choice for packaging our services into containers. We have found this to be an excellent tool for achieving both high security and performance, providing fast builds of distro-less containers with an SBOM generated by default.
One of our challenges to date has been to provide seamless and fully integrated operations tooling for our SREs. At Einride, we apply the SRE-without-SRE approach: engineers who develop a service also operate it. When you wake up in the middle of the night to handle an alert, you need the best possible tooling available to diagnose the problem. That’s why we decided to leverage the full Cloud Operations suite, giving our SREs access to logging, monitoring, tracing, and even application profiling. The challenge has been to build this into each and every backend service in a consistent way. For that, we developed the Cloud Runner SDK for Go – a library that automatically configures the integrations and even fills in some of the gaps in the default Cloud Run monitoring, ensuring we have all four golden signals available for gRPC services.
For storage, we found that the Go library ecosystem around Cloud Spanner provided us with the best end-to-end development experience. We chose Spanner for its ease of use and low management overhead – including managed backups, which we were able to automate with relative ease using Cloud Scheduler. Building our applications on top of Spanner has provided high availability for our applications, as well as high trust for our customers and investors.
Using protocol buffers to create schemas for our data has allowed us to build a data lake on top of BigQuery, since our raw data is strongly typed. We even developed an open-source library to simplify storing and loading protocol buffers in BigQuery. To populate our data lake, we stream data from our applications and trucks via Pub/Sub. In most cases, we have been able to keep our ELT pipelines simple by loading data through stateless event handlers on Cloud Run.
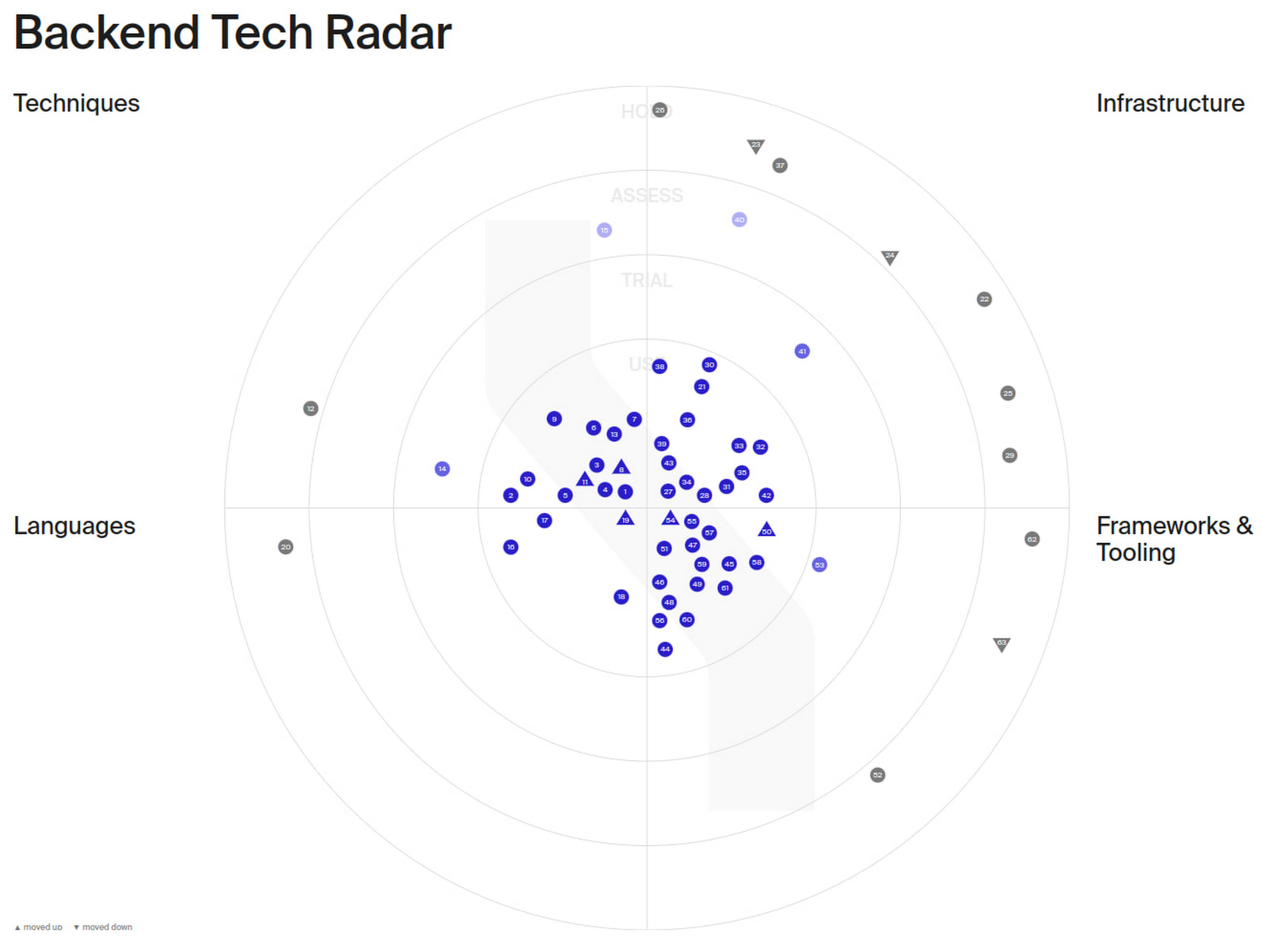
The list of serverless technologies we’ve leveraged at Einride goes on, and keeping track of them is a challenge of its own – especially for new developers joining the team who don’t have the historical context of technologies we’ve already assessed. We built our tech radar tool to curate and document how we develop our backend services, and perform regular reviews to ensure we stay on top of new technologies and updated features.
Einride’s backend tech radar, a tool used by Einride to curate and document their serverless tech stack.
But the journey is far from over. We are constantly evolving our tech stack and experimenting with new technologies on our tech radar. Our future goals include increasing our software supply chain security and building a fully serverless data mesh. We are currently investigating how to leverage ko and Cloud Build to achieve SLSA level 2 assurance in our build pipelines and how to incorporate Dataplex in our serverless data mesh.
A freight industry reimagined with serverless
For Einride, being at the cutting edge of adopting new serverless technologies has paid off. It’s what’s enabled us to grow from a startup to a company scaling globally without any investment into building our own infrastructure teams.
Industry after industry is being transformed by software, including complex industries that have more physical hardware and require more human interaction. To succeed, we must learn from the industries that came before us, recognize the patterns, and apply the most successful solutions.
In our case, it has been possible not just by building our own platform with a serverless architecture, but also by taking the core ideas of serverless and applying them to the freight industry as a whole.
Photoshop is one of the top graphic software on the market. Photoshop has surprising capabilities that professionals and hobbyists enjoy. You can convert a low-resolution logo to a high-resolution vector graphic in Photoshop. Photoshop is supposed to be for raster color but here is another surprise, it can also do some amount of vector graphic. […]
Microsoft Teams is getting a new update that will enable IT admins to deploy and manage teams at scale. Microsoft has announced in a message on the Microsoft 365 admin center that administrators will be able to create up to 500 teams with built-in or custom templates via Teams PowerShell cmdlet.
Specifically, Microsoft Teams will allow IT Pros to add up to 25 users to teams as members or owners. The upcoming update will also make it possible to add or remove members from existing teams. Moreover, admins will be able to send email notifications about the deployment status of each batch to up to 5 people.
Microsoft Teams’ new feature will make team management easier for IT admins
According to Microsoft, the ability to create and manage large numbers of teams at a time should help to significantly reduce deployment time. It will also make it easier for organizations to meet the specific scalability needs of their organization.
“Your organization may have a lot of teams that you use to drive communication and collaboration among your frontline workforce, who are spread across different stores, locations, and roles. Currently, there isn’t an easy solution to deploy, set up, and manage these teams and users at scale,” the company explained on the Microsoft 365 admin center.
Microsoft notes that this feature is currently under development, and it will become available for Microsoft Teams users in preview by mid-September. However, keep in mind that the timeline is subject to change.
Microsoft is also introducing a feature that will let users start group chats with the members of a distribution list, mail-enabled security group, or Microsoft 365 groups in Teams. Microsoft believes that this release will help to improve communication and boost the workflow efficiency of employees. You can check out our previous post for more details.
RISC OS Developments have been working away on their new TCP/IP stack for some time now and it is available to download from their website. So it seemed high time for TIB to wander over and have a look.
Installing the software The software is available as a zip download.
I would recommend reading the !!Read_Me_First text file (which also tells you how to remove from your system). The Reporting Document tells you how to report any bugs you might find. Features gives you a nice overview and a clear idea of the objectives with this software.
When you are ready to try, Double-click on !Install and follow the prompts, rebooting your machine.
In use The first indication that things have changed is that you have new options with Interfaces menu compared to previously.
You will also find that it has thoughtfully backed up your old version, just in case…
First impressions I do not have an IP6 setup so my main interest was in updating my existing setup (and being generally nosy). For IP4, this is a drop in replacement. Everything works as before (feels subjectively faster) and it all works fine. Like all the best updates, it is very boring (it just works). RISC OS Developments have done an excellent job of making it all painless. While the software is still technically in beta, I have no issues running on my main RISC OS machine.
What is really exciting is the potential this software opens up of having a maintained and modern TCP/IP stack with support for modern protocols, TCP/IP 6 and proper wifi support.
As per MC407050, Microsoft is going to retire the “Connect to Exchange Online PowerShell with MFA module” (i.e., EXO V1 module) on Dec 31, 2022. And the support ends on Aug 31, 2022. So, admins should move to EXO V2 module to connect to Exchange Online PowerShell with multi-factor authentication.
Why We Should Switch from EXO V1 Module?
Admins should install the Exchange Online remote PowerShell module and use the PowerShell cmdlet Connect-EXOPSSession to connect to Exchange Online PowerShell with MFA. The module uses basic authentication to connect to EXO. Due to basic authentication deprecation, Microsoft has introduced the EXO V2 module with improved security and data retrieval speed.
Connect to Exchange Online PowerShell with MFA:
To connect to Exchange Online PowerShell with MFA, you need to install the Exchange Online PowerShell V2 module. With this module, you can create a PowerShell session with both MFA and non-MFA accounts using the Connect-ExchangeOnline cmdlet.
Additionally, the Exchange Online PowerShell V2 module uses modern authentication and helps to create unattended scripts to automate the Exchange Online tasks.
To download and install the EXO V2 module & connect to Exchange Online PowerShell, you can use the script below.
#Check for EXO v2 module installation
$Module = Get-Module ExchangeOnlineManagement -ListAvailable
if($Module.count -eq 0)
{
Write-Host Exchange Online PowerShell V2 module is not available -ForegroundColor yellow
$Confirm= Read-Host Are you sure you want to install module? [Y] Yes [N] No
if($Confirm -match "[yY]")
{
Write-host "Installing Exchange Online PowerShell module"
Install-Module ExchangeOnlineManagement -Repository PSGallery -AllowClobber -Force
Import-Module ExchangeOnlineManagement
}
else
{
Write-Host EXO V2 module is required to connect Exchange Online. Please install module using Install-Module ExchangeOnlineManagement cmdlet.
Exit
}
}
Write-Host Connecting to Exchange Online...
Connect-ExchangeOnline
If you have already installed the EXO V2 module, you can use the “Connect-ExchangeOnline” cmdlet directly to create a PowerShell session with MFA and non-MFA accounts. For MFA accounts, it will prompt for additional authentication. After the verification, you can access Exchange Online data and Microsoft 365 audit logs.
Advantages of Using EXO V2 Module:
It uses modern authentication to connect to Exchange Online PowerShell.
A single cmdlet “Connect-ExchangeOnline” is used to connect to EXO with both MFA and non-MFA accounts.
It doesn’t require WinRM basic authentication to be enabled.
Helps to automate EXO PowerShell login with MFA. i.e., unattended scripts.
Contains REST API based cmdlets.
Provides exclusive cmdlets that are optimized for bulk data retrieval.
If you are using the Exchange Online Remote PowerShell module, it’s time to switch to the EXO V2 module. Also, you can update your existing scripts to adopt the EXO V2 module. Happy Scripting!
OK yall so I gotta ask as wild fires are scary as shit and they claim alot of my state as well as others each year… that stated, any that do off grid setups have you thought of anti fire precautions?
Below I have outlined a simple 10 dollar (does 100s of hotspots for 15 bucks lol)
OK ingredients per hotspot: -Bromochlorodifluoromethane powder> about 5 to 8 grams per Hotspot needed (1kilo is like 5 bucks max on alibaba)
-1 water Ballon> or any Ballon with extremely thin rubber on the walls just need it to pop very very easy
one small firecracker firework> the kind you get in a pack of 40 and it says ‘caution: don’t unpack the thing light as one’ or what ever it says but we all do it anyways cuz we are not as smart of creatures as we think we are 😆
-firework wick> you will use like 2 or 3 foot give or take per hotspot (a 10m rolls like 3 or 4 bucks I think almost anywhere that sells it)
-1 tiny sized rubber hair band per hotspot> the Lil Lil tiny ones that are like the size of a pinky finger round (a packs 50 cents at family dollar or use o-rings if you are a tool guy and have lil tiny o-rings)
-You need a balloon for when you fill the "homemade fire snuffer bomb" (patent pending) jkjk 😆
-you need a few straw for filling as well (and a small cardboard that can crease but stay ridged will help but can be done with out)
-peel apart bread ties or a roll of sone other very thin wire
OK so see we got about 15$USD of materials here, what your gunna do is…
1) put on gloves and at least a dust particulate 3m mask and some rubber gloves!
PSA of the day! –>(your bodies worth it and that powder is not really supposed to be huffed no matter the intent to or accidental …..cancer don’t care. Cancer happens either way if your adult dont be lazy get in the car or on the bicycle or long board like us millennials do so frequently it seems…. just go buy a pair of 99cent kitchen dish gloves at family dollar, and if you a kid then steal moms from under the sink for 20 mins it wont destroy them just rinse and return)
Now….
2) you are going to take said Bromochlorodifluoromethane powder and put around 7-10 grams in a ballon (this is where the carboard folded in a square angle crease comesin handy but if you skiped it take the drinking straw and use it to scoop a few grams at a time into the balloon)
Then…
3) take the pack of fire crackers apart and strip them into single firecracker units.
4) take 3ish foot of wick off the roll and then attach it to the wick of one fire cracker (overlap the two wicks so that the overlap about a inch then use a piece of wire to wrap around it In a spirl fashion from the fire cracker to the 3ish foot piece secure it as best you can so it will make good contact if triggered to activate save the day for some random forrest or nieghborhood or where ever it be!)
Now set that aside and return to the powder filled balloon…
5) get a hair band ready and have the extra balloon *** make sure its a powder free clean balloon*** I mentioned that it was for the help in filling in the list at the start!
6) blow into the clean Balloon enough so it’s the size off a orange or a apple or baseball or what ever you want to picture it as that’s that size… (***Big Tip: I use tape, after I blow in it, so I can put on a table edge and duck tape the thing to the table so it stays filled but can be removed and let deflate when ready😉)
OK on to…
7) place firecracker in the powder balloon shove it in the middle so that it is completely surrounded by the powder, but leave the long wick hanging out the balloon!
8)**** put a clean straw**** in the powder balloon (you dont want it contaminated on both ends if you used for filling with it!) Then put the hairband looped multiple times on its self (objective is: to have the band wrapped enough so once on the balloon neck and you pull the straw out you have a tightly sealed water balloon this is so it holds a slight amount of air)
9) take the clean air filled balloon from [step 6)] and then put on the opposing end of the straw snug as you can without to much air loss… squeeze air into the the powder Balloon from the air Balloon (if it is hard to get that much in due to loss when putting it on straw then fill the air balloon more and go round 2)
Finally….
10) when powder balloon is inflated slightly think like tennis ball ish sized and you feel it feel like a balloon when you squish lightly on it (not like a hackie sack more one of those bags of air that products get shipped with the ones that are a string of like seven bags of air…. I digress you get the picture) pull the straw when you are happy and you now have a homemade class D fire extinguisher….
Place that bad boy inside the housing of the miner and battery set up and drape the wick so it is laying all around the inside the enclosure you use.
Battery vents>wick gets lit by the battery igniting>firecracker goes #pop>powder from previously inflated balloon fills box> Battery fire fixed in a matter of 5 or less seconds from start of fire
That said if your yseing a big housing enclosure plan accordingly by your specs in size of enclosure… if it’s a big space maybe put 2 fire snuffer bombs in each be smart the nature your putting it in will prefer to not have a fire filled future in the event its a needed precaution!
There ya go!
thanks for the read If you made it to the end. That’s my solution lmk what yall did if you had a good solution as well! I’d love to hear it 😀
RISCOSbits have announced their new RISC OS rewards scheme. The idea is to reward loyal RISC OS users by offering them discounts on new RISC OS hardware.
To start with, they are offering anyone who can show they have purchased an Ovation Pro licence a 10% discount on any PiHard systems. We have previously reviewed the PiHard (which is now my main RISC OS machine at work and what I am typing this on).
This offer is also open to any existing RISCOSbits customers, who can also claim 10% on anew system.
To claim your discount, you should contact RISCOSbits directly.
There will be additional special offers. If you are on twitter, watch out for the hashtag #RISC_OS_Rewards
“Everything fails, all the time”, a famous quote from Werner Vogels, Vogles, VP and CTO of Amazon.com. When you design and build an application, a typical goal is to have it working, the next is to keep it running, no matter what disruptions may occur. It is crucial to achieve resiliency, but you need to consider how to define it first and which metric to use to determine your application’s resiliency against. Resiliency can be defined in terms of metrics called RTO (Recovery Time Objective) and RPO (Recovery Point Objective). RTO is a measure of how quickly can your application recover after an outage and RPO is a measure of the maximum amount of data loss that your application can tolerate.
AWS Resilience Hubis a new service launched in November 2021. This service is designed to help you define, validate and track the resilience of your applications on the AWS cloud.
You can define the resilience policiesfor your applications. These policies include RTO and RPO targets for applications, infrastructure, availability zone, and region disruptions. Resilience Hub’s assessment uses best practices from the AWS Well-Architected Framework. It will analyze the components of an application such as compute, storage, database and network and uncover potential resilience weaknesses.
In this blog we will show you how Resilience Hub can help you validate RTO and RPO at component level for four types of disruptions, which in-turn can help you improve the resiliency of your entire application stack.
Customer Application RTO and RPO
AWS Infrastructure RTO and RPO
Cloud Infrastructure Availability Zone (AZ) disruption
AWS Region disruption
outage
AWS Infrastructure Region outage
Customer Application RTO and RPO
Application outages occur when the infrastructure stack (hardware) is healthy but the application stack (software) is not. This outage may be caused by configuration changes, bad code deployments, integration failures, etc. Determining RTO and RPO for application stacks depends on the criticality and importance of the application, as well as your compliance requirements. For example, mission critical application could have an RTO and RPO of 5 minutes
Example: Your critical business application is hosted from Amazon Simple Storage Service (Amazon S3)bucket and you set it up without cross region replication and versioning. Figure 1 shows that application RTO and RPO are unrecoverable based on a target of 5 minutes RTO and RPO
Figure 1. Resilience Hub assessment of the Amazon S3 bucket against Application RTO
After running the assessment, Resilience Hub provides recommendation to enable versioning on Amazon S3 bucket as shown in Figure 2.
Figure 2. Resilience recommendation for Amazon S3
After enabling the versioning, you can achieve the estimated RTO of 5m and RPO RTO of 0s. Versioning allows you to preserve, retrieve, and restore any version of any object stored in a bucket improving your application resiliency.
Resilience Hub also provides the cost associated with implementing the recommendations. In this case, there is no cost for enabling versioning on Amazon S3 bucket. Normal S3 pricing applies to each version of an object. You can store any number of versions of the same object, so you may want to implement some expiration and deletion logic if you plan to make use of versioning.
Resilience Hub can provide one or more than one recommendation to satisfy the requirements such as cost, high availability and least changes. As shown in Figure 2, adding versioning for S3 bucket satisfies both high availability optimization and best attainable architecture with least changes.
Cloud Infrastructure RTO and RPO
Cloud Infrastructure outage occurs when the underlying components for infrastructure, such as hardware fail. Consider a scenario where a partial outage occurred because of a component failure.
For example, one of the components in your mission critical application is anAmazon Elastic Container Service (ECS)running on Elastic Compute Cloud (EC2) instance, and your targeted infrastructure RTO and RPO of 1 second .Figure 3 shows that you are unable to meet your targeted infrastructure RTO of 1 second
Figure 3. Resilience Hub assessment of the ECS application against Infrastructure
Figure 4. Resilience Hub recommendation for ECS cluster – to add Auto Scaling Groups and Capacity providers in multiple AZs.
AWS Auto Scaling monitors your applications and automatically adjusts capacity to maintain steady, predictable performance at the lowest possible cost. Amazon ECS capacity providers are used to manage the infrastructure the tasks in your clusters use. It can use AWS Auto Scaling groups to automatically manage the Amazon EC2 instances registered to their clusters. By applying the Resilience Hub recommendation, you will achieve an estimated RTO and RPO of near zero seconds and the estimated cost for the change is $16.98/month.
AWS Infrastructure Availability Zone (AZ) disruption outage
The AWS global infrastructure is built around AWS Regions and Availability Zone to achieve High Availability (HA). AWS Regions provide multiple physically separated and isolated Availability Zones, which are connected with low-latency, high-throughput, and highly redundant networking.
For example, you have setup a public NAT gateway in Single-AZ Single-Az to allow instances in a private subnet to send outbound traffic to the internet. You have deployed Amazon Elastic Compute Cloud (Amazon EC2)instances in multiple availability zones.
Figure 5. Resilience Hub assessment of the Single-Az NAT gateway
Figure 5 shows Availability Zone disruptions as unrecoverable and does not meet the Availability Zone RTO goals. NAT gateways are fully managed services, there is no hardware to manage, so they are resilient (0s RTO) for infrastructure failure. However, deploying only one NAT gateway in Single AZ Az leaves the architecture vulnerable. If the NAT gateway’s Availability Zone is down, resources deployed in other Availability Zones lose internet access.
Figure 6 shows Resilience Hub’s recommendation to deploy NAT Gateways into each Availability Zone where corresponding EC2 resources are located.
Following Resilience Hub’s recommendation, you can achieve the lowest possible RTO and RPO of 0 seconds in the event of an Availability Zone disruption and create an Availability Zone-independent architecture run on $32.94 per month.
NAT Gateway deployment in multiple Azs can achieve the lowest RTO/RPO for Availability Zone disruption, the lowest cost, and the minimal changes, so the recommendation is the same for all three options.
AWS Region disruption outage
An AWS Region consists of multiple, isolated, and physically separated AZs within a geographical area. This design achieves the greatest possible fault tolerance and stability. For a disaster event that includes the risk of disruption of multiple data centers or a regional service disruption, losing multiple data centers, it’s a best practice to consider multi-region disaster recovery strategy to mitigate against natural and technical disasters that can affect an entire Region within AWS. If one or more Regions or regional service that your workload uses are unavailable, this type of disruption outage can be resolved by switching to a secondary Region. It may be necessary to define a regional RTO and RPO if you have a Multi-Region dependent application.
For example, you have a Single-AZ Single-AzAmazon RDS for MySQLas part of a global mission-critical application and you have configured 30 min RTO and 15 minute RPO for all four disruption types. Each RDS instance runs on an Amazon EC2instance backed by an Amazon Elastic Block Store (Amazon EBS)volume for storage. RDS takes daily snapshots of the database, which are stored durably in Amazon S3 behind the scenes. It also regularly copies transaction logs to S3—up to 5 min utes intervals—providing point-in time-recovery when needed.
If an underlying EC2 instance suffers a failure, RDS automatically tries to launch a new instance in the same Availability Zone, attach the EBS volume, and recover. In this scenario, RTO can vary from minutes to hours. The duration depends on the size of the database, and failure and recovery approach. RPO is zero in the case of recoverable instance failure because the EBS volume was recovered. If there is an Availability Zone disruption, you can create a new instance in a different Availability Zone using point-in-time recovery. Single-AZ Single-Az does not give you protections against regional disruption. distribution. Figure 7 shows that you are not able to meet regional RTO of 30 min and RPO of 15 mins.
Figure 7. Resilience Hub assessment for the Amazon RDS
Figure 8. Resilience Hub recommendation to achieve region level RTO and RPO
As shown in Figure 8, Resilience Hub provides you three recommendations to optimize in order to handle Availability Zone disruptions, be cost effective and to have minimal changes.
Recommendation 1 “Optimize for Availability Zone RTO/RPO”: The changes recommended under this option will help you achieve the lowest possible RTO and RPO in the event of an Availability Zone disruption. For a Single-AZ Single-Az RDS, Resilience Hub recommends to change the Database to Aurora and add two read replica same region to achieve targeted RTO and RPO for Availability Zone failure. It also recommends to add a read replica in different region to achieve resiliency for regional disruption. Estimated cost for these changes as shown in Figure 8 is $66.85 per month.
Amazon Auroraread replicas share the same data volume as the original database instance. Aurora handles the Availability Zone disruption by fully automating the failover with no data loss. Aurora creates highly available database cluster with synchronous replication across multiple AZs. This is considered to be the better option for production databases where data backupis a critical consideration.
Recommendation 2 “Optimize for cost”: These changes will optimize your application to reach the lowest cost that will still meet your targeted RTO and RPO. The recommendation here is to keep a Single-AZ Single-Az Amazon RDS and create the read replica in primary region with additional read replica in the secondary / different region. The estimated cost for these changes is $54.38 per month. You can promote a read replica to a standalone instance as a disaster recovery solution if the primary DB instance fails or unavailable during region disruption.
Recommendation 3 “Optimize for minimal changes”: These changes will help you to meet targeted RTO and RPO while keeping implementation changes to minimal. Resilience Hub recommends to create a Multi-AZ Multi-Az writer and a Multi-AZ Multi-Az read replicain two different regions. Estimate cost for changes is $81.56 per month. When you provision a Multi-AZ Multi-Az Database instance, Amazon RDS automatically creates a primary Database instance and synchronously replicates the data to a standby instance in a different Availability Zone. In case of an infrastructure failure, Amazon RDS performs an automatic failover to the standby Database instance. Since the endpoint for your Database instance remains the same after a failover, your application can resume database operation without the need for manual administrative intervention
Although all three recommendations help you achieve a targeted application RTO and RPO of 30 mins, the estimated costs and efforts may vary.
Conclusion
To build a resilient workload, you need to have right best practices in place. In this post, we showed you how to improve the resiliency of your business application and achieve targeted RTO and RPO for application, infrastructure, Availability Zone, and Region disruptions using recommendations provided by Resilience Hub. To learn more and try the service by yourself, visit AWS Resilience Hubpage.
Need to search for a string inside a string? Never fear, PowerShell substring is here! In this article, I guide you through how to ditch objects and search inside strings.
The PowerShell substring
I love being on social media because I always come across something interesting related to PowerShell. Sometimes it is a trick I didn’t know about or a question someone is trying to figure out. I especially like the questions because it helps me improve my understanding of how people learn and use PowerShell. Workload permitting, I’m happy to jump in and help out.
One such recent challenge centered on string parsing. Although you’ll hear me go on and on about object in the pipeline, there’s nothing wrong with parsing strings if that’s what you need. There are plenty of log files out there that need parsing, and PowerShell can help.
Search for a string in a string
In this case, I’m assuming some sort of log file is in play. I don’t know what the entire log looks like or what the overall goal is. That’s OK. We can learn a lot from the immediate task. Let’s say you have a string that looks like this:
I’ve changed the values a little bit and modified my name to make it more challenging. The goal is to grab the name from the string. I want to end up with:
O'Hicks, Jeffery(X.)
There are several different ways you can accomplish this. The right way probably depends on your level of PowerShell experience and what else you might want to accomplish. I’ll start by assigning this string to variable $s.
Using the PowerShell split operator
When I am faced with string parsing, sometimes it helps to break the string down into more manageable components. To do that I can use the split operator. There is also a split method for the string class. I am going to assume you will take some time later to read more about PowerShell split.
$s -split "\s",2
The “\s” is a regular-expression pattern that means a space. The 2 parameter value indicates that I only want two substrings. In other words, split on the first space found.
Using the split operator in Windows PowerShell. (Image Credit: Jeff Hicks)
I end up with an array of two elements. All I need is the second one.
$t = ($s -split "\s",2)[1]
Using the substring method
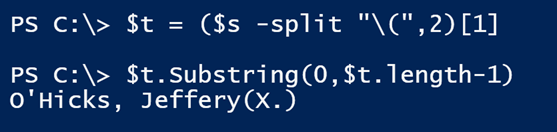
Now for the parsing fun, let’s use the string object’s SubString() method.
$t.Substring(1,$t.length-2)
I am telling PowerShell to get part of the string in $t, starting at character position 1 and then getting the next X number of characters. In this case, X is equal to the length of the string, $t, minus 2. This has the net effect of stripping off the outer parentheses.
Using the PowerShell substring method (Image Credit: Jeff Hicks)
Here’s a variation, where I split on the “(” character.
Using the split operator on a character in Windows PowerShell. (Image Credit: Jeff Hicks)
The difference that this gets rid of the leading parenthesis. So, all I need to do is get everything up to the last character. By the way, if you look at a string object with Get-Member, you will see some Trim methods. These are for removing leading and/or training white space. Those methods don’t apply here.
Split a string using array index numbers
There’s one more way to split a string that you might find useful. You can treat all strings as an array of characters. This means you can use array index numbers to reference specific array elements.
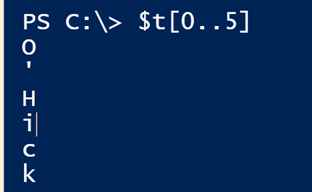
Counting elements in an array starts at 0. If you run $t[0] you’ll get the first element of the array, in this case ‘O’. You can also use the range operator.
$t[0..5]
An alternative to splitting a string in Windows PowerShell. (Image Credit: Jeff Hicks)
Right now, $t has an extra ) at the end that I don’t want. I need to get everything up to the second-to-last element.
$t[0..($t.length-2)]
This will give me an array displayed vertically, which you can see in the screenshot above. With that said, it’s easy to join the spliced string back together.
-join $t[0..($t.length-2)]
It might look a bit funny to lead with an operator, but if you read about_join, then you’ll see this is a valid approach that works.
Using the -join operator to put our string back together. (Image Credit: Jeff Hicks)
Simple function for string parsing
I’m assuming you want an easy way to do this type of parsing, so I wrote a simple function.
Function Optimize-String {
[cmdletbinding()]
Param(
[Parameter(Position=0,Mandatory,HelpMessage="Enter a string of text")]
[ValidateNotNullorEmpty()]
[string]$Text,
[int]$Start=0,
[int]$End=0
)
#trim off spaces
$string = $Text.Trim()
#get length value when starting at 0
$l = $string.Length-1
#get array elements and join them back into a string
-join $string[$Start..($l-$end)]
} #end function
The function takes a string of text and returns the substring minus X number of characters from the start and X number of characters from the end. Now I have a easy command to parse strings.
Using the optimize-string function in Windows PowerShell. (Image Credit: Jeff Hicks)
If you look through the code, then you’ll see I am using the Trim() method. I am using it because I don’t want any extra spaces at the beginning or end of the string to be included.
Going back to my original string variable, I can now parse it with a one-line command:
The content below is taken from the original ( Palo Alto Virtual Lab), to continue reading please visit the site. Remember to respect the Author & Copyright.
I have seen several posts asking about virtual lab costs, etc…
When I saw my daily Fuel email it reminded me of those posts.
If you are looking to become certified or just want to learn more about PAs, I would recommend joining your local Fuel User Group Chapter. go to https://fuelusergroup.org and sign up, its free. Now that you have an account you can access resources and you will get a local rep to help you on your learning journey. One of the resources you gain is free access to a virtual lab.
Fuel User Group is great. Meet all kinds of IT professionals, vendors, and Palo Reps. Hold on to those reps because they have access to Palo people that you and I do not, plus they may also know other professionals with the knowledge you’re looking for. I am looking forward to getting back to our in person meetings. In the meetings they bring great PA information and yes, they do have a sponsor doing a short pitch but honestly they fit the vibe of the meeting. Time is not wasted and the swag is great!








 Did you know you can map useful commands to your keyboard? Follow this guide to learn how.
Did you know you can map useful commands to your keyboard? Follow this guide to learn how.