[Andy]’s robot is an autonomous RC car, and he shares the localization algorithm he developed to help the car keep track of itself while it zips crazily around an indoor racetrack. Since a robot like this is perfectly capable of driving faster than it can sense, his localization method is the secret to pouring on additional speed without worrying about the car losing itself.
The regular pattern of ceiling lights makes a good foundation for the system to localize itself.
To pull this off, [Andy] uses a camera with a fisheye lens aimed up towards the ceiling, and the video is processed on a Raspberry Pi 3. His implementation is slick enough that it only takes about 1 millisecond to do a localization update, netting a precision on the order of a few centimeters. It’s sort of like a fast indoor GPS, using math to infer position based on the movement of ceiling lights.
To be useful for racing, this localization method needs to be combined with a map of the racetrack itself, which [Andy] cleverly builds by manually driving the car around the track while building the localization data. Once that is in place, the car has all it needs to autonomously zip around.
Interested in the nitty-gritty details? You’re in luck, because all of the math behind [Andy]’s algorithm is explained on the project page linked above, and the GitHub repository for [Andy]’s autonomous car has all the implementation details.
The system is location-dependent, but it works so well that [Andy] considers track localization a solved problem. Watch the system in action in the two videos embedded below.
This first video shows the camera’s view during a race.
This second video is what it looks like with the fisheye lens perspective corrected to appear as though it were looking out the front windshield.
The content below is taken from the original ( London Show next Saturday), to continue reading please visit the site. Remember to respect the Author & Copyright.
Organised as an online event last year because of the pandemic, the RISC OS London Show is returning to the physical world this year, and will take place on Saturday,… Read more »
The content below is taken from the original ( Self hosted monitor/status page), to continue reading please visit the site. Remember to respect the Author & Copyright.
It’s been a few days now since Facebook, Instagram, and WhatsApp went AWOL and experienced one of the most extended and rough downtime periods in their existence.
When that happened, we reported our bird’s-eye view of the event and posted the blog Understanding How Facebook Disappeared from the Internet where we tried to explain what we saw and how DNS and BGP, two of the technologies at the center of the outage, played a role in the event.
In the meantime, more information has surfaced, and Facebook has published a blog post giving more details of what happened internally.
As we said before, these events are a gentle reminder that the Internet is a vast network of networks, and we, as industry players and end-users, are part of it and should work together.
In the aftermath of an event of this size, we don’t waste much time debating how peers handled the situation. We do, however, ask ourselves the more important questions: “How did this affect us?” and “What if this had happened to us?” Asking and answering these questions whenever something like this happens is a great and healthy exercise that helps us improve our own resilience.
Today, we’re going to show you how the Facebook and affiliate sites downtime affected us, and what we can see in our data.
1.1.1.1
1.1.1.1 is a fast and privacy-centric public DNS resolver operated by Cloudflare, used by millions of users, browsers, and devices worldwide. Let’s look at our telemetry and see what we find.
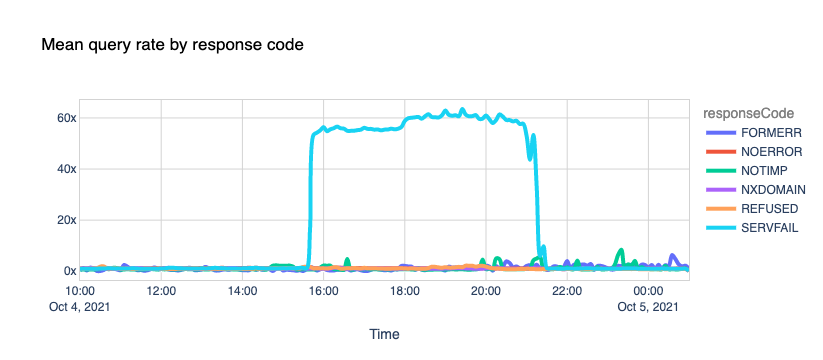
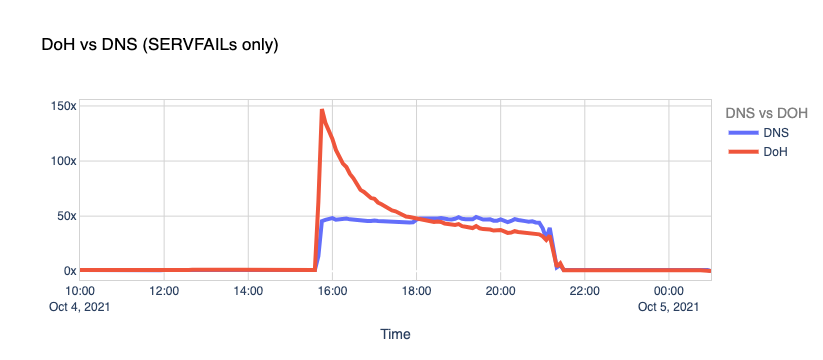
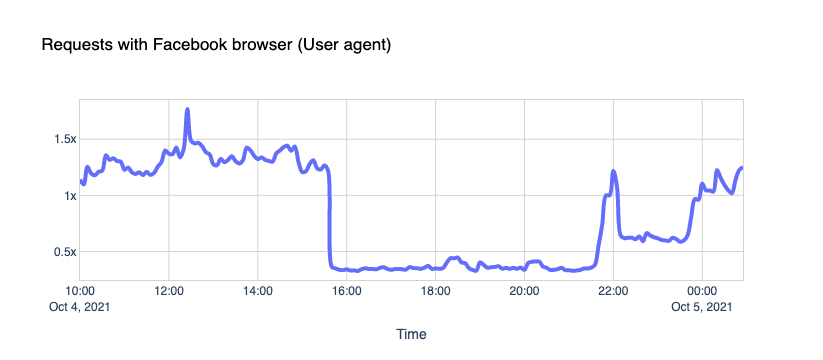
First, the obvious. If we look at the response rate, there was a massive spike in the number of SERVFAIL codes. SERVFAILs can happen for several reasons; we have an excellent blog called Unwrap the SERVFAIL that you should read if you’re curious.
In this case, we started serving SERVFAIL responses to all facebook.com and whatsapp.com DNS queries because our resolver couldn’t access the upstream Facebook authoritative servers. About 60x times more than the average on a typical day.
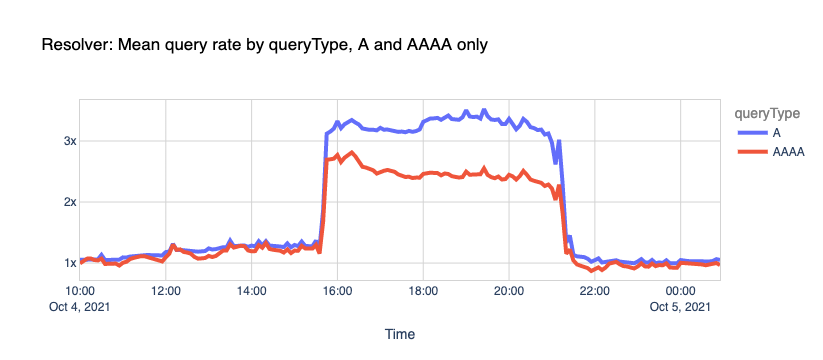
If we look at all the queries, not specific to Facebook or WhatsApp domains, and we split them by IPv4 and IPv6 clients, we can see that our load increased too.
As explained before, this is due to a snowball effect associated with applications and users retrying after the errors and generating even more traffic. In this case, 1.1.1.1 had to handle more than the expected rate for A and AAAA queries.
Here’s another fun one.
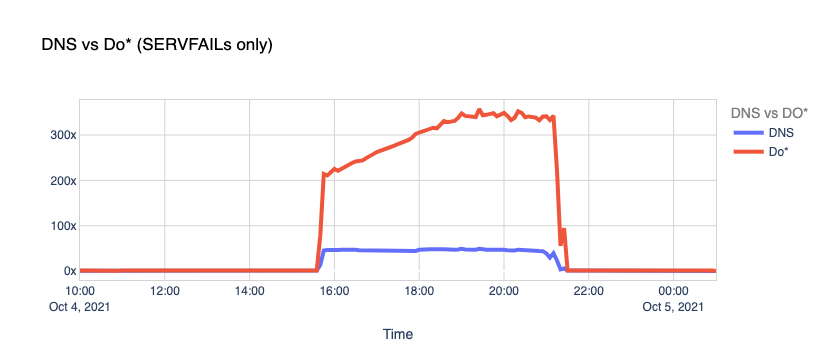
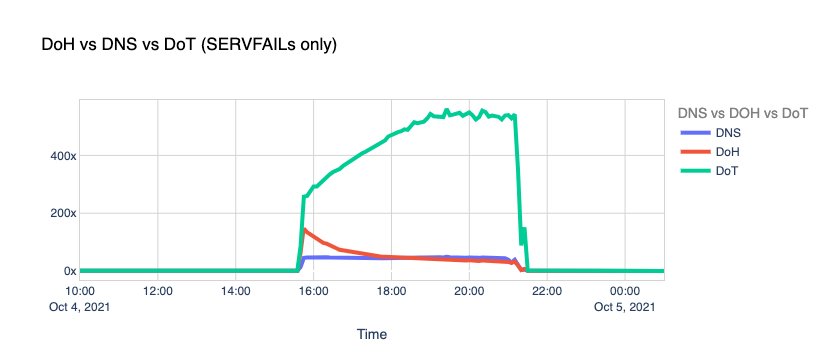
DNS vs. DoT and DoH. Typically, DNS queries and responses are sent in plaintext over UDP (or TCP sometimes), and that’s been the case for decades now. Naturally, this poses security and privacy risks to end-users as it allows in-transit attacks or traffic snooping.
With DNS over TLS (DoT) and DNS over HTTPS, clients can talk DNS using well-known, well-supported encryption and authentication protocols.
Our learning center has a good article on “DNS over TLS vs. DNS over HTTPS” that you can read. Browsers like Chrome, Firefox, and Edge have supported DoH for some time now, WAP uses DoH too, and you can even configure your operating system to use the new protocols.
When Facebook went offline, we saw the number of DoT+DoH SERVFAILs responses grow by over x300 vs. the average rate.
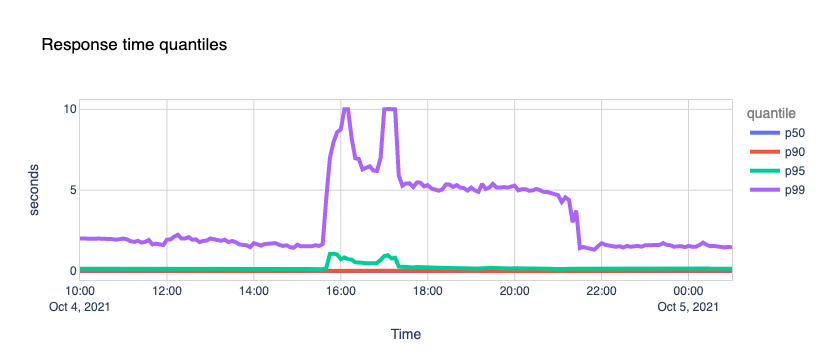
So, we got hammered with lots of requests and errors, causing traffic spikes to our 1.1.1.1 resolver and causing an unexpected load in the edge network and systems. How did we perform during this stressful period?
Quite well. 1.1.1.1 kept its cool and continued serving the vast majority of requests around the famous 10ms mark. An insignificant fraction of p95 and p99 percentiles saw increased response times, probably due to timeouts trying to reach Facebook’s nameservers.
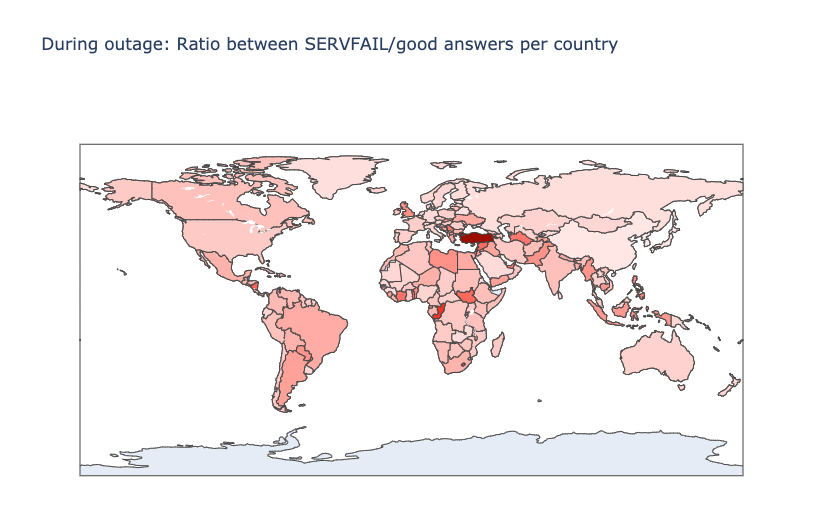
Another interesting perspective is the distribution of the ratio between SERVFAIL and good DNS answers, by country. In theory, the higher this ratio is, the more the country uses Facebook. Here’s the map with the countries that suffered the most:
Here’s the top twelve country list, ordered by those that apparently use Facebook, WhatsApp and Instagram the most:
Country
SERVFAIL/Good Answers ratio
Turkey
7.34
Grenada
4.84
Congo
4.44
Lesotho
3.94
Nicaragua
3.57
South Sudan
3.47
Syrian Arab Republic
3.41
Serbia
3.25
Turkmenistan
3.23
United Arab Emirates
3.17
Togo
3.14
French Guiana
3.00
Impact on other sites
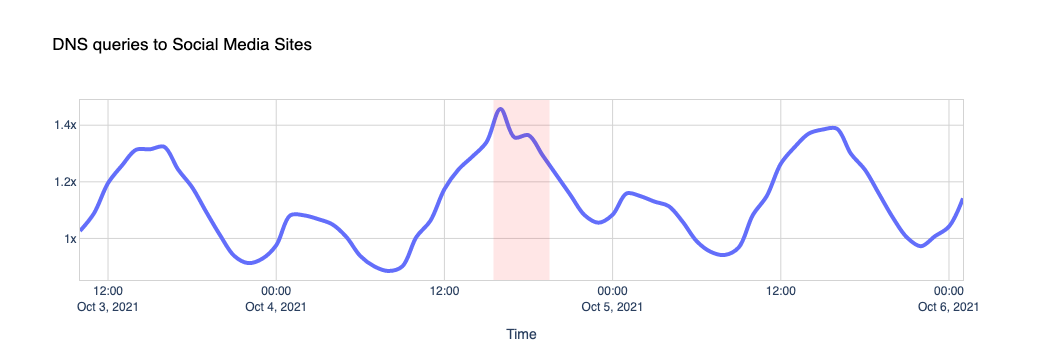
When Facebook, Instagram, and WhatsApp aren’t around, the world turns to other places to look for information on what’s going on, other forms of entertainment or other applications to communicate with their friends and family. Our data shows us those shifts. While Facebook was going down, other services and platforms were going up.
To get an idea of the changing traffic patterns we look at DNS queries as an indicator of increased traffic to specific sites or types of site.
Here are a few examples.
Other social media platforms saw a slight increase in use, compared to normal.
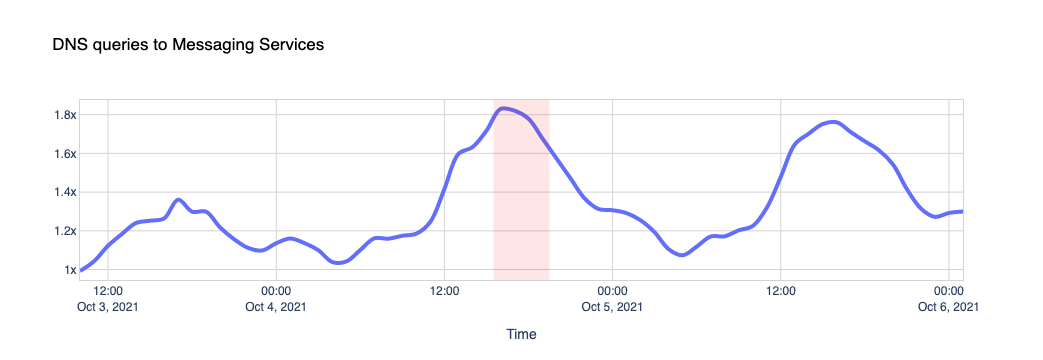
Traffic to messaging platforms like Telegram, Signal, Discord and Slack got a little push too.
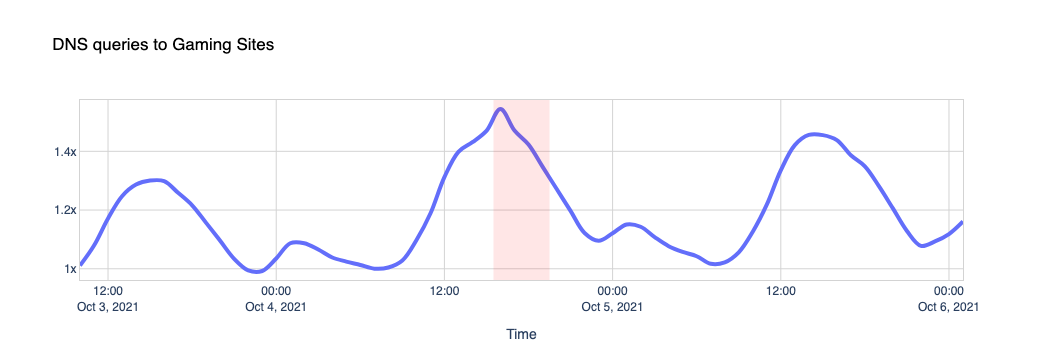
Nothing like a little gaming time when Instagram is down, we guess, when looking at traffic to sites like Steam, Xbox, Minecraft and others.
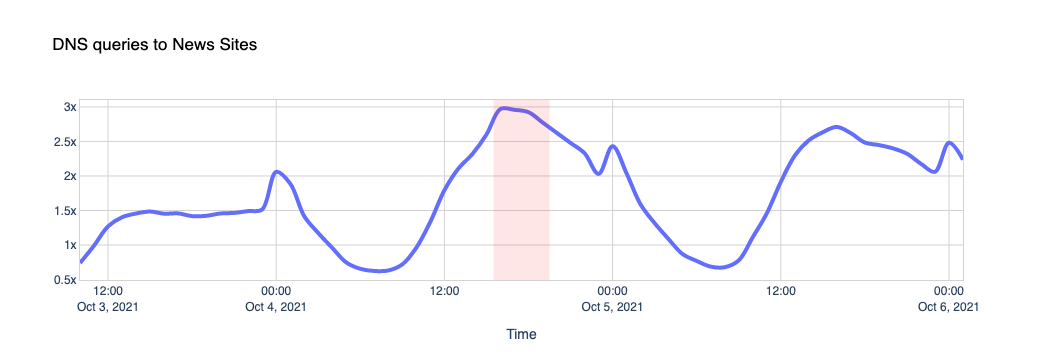
And yes, people want to know what’s going on and fall back on news sites like CNN, New York Times, The Guardian, Wall Street Journal, Washington Post, Huffington Post, BBC, and others:
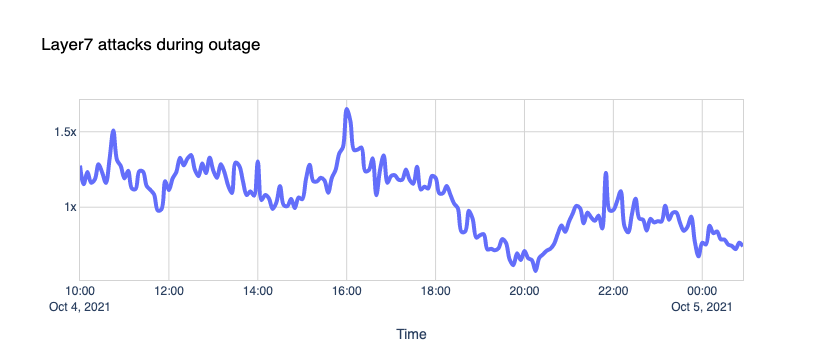
Attacks
One could speculate that the Internet was under attack from malicious hackers. Our Firewall doesn’t agree; nothing out of the ordinary stands out.
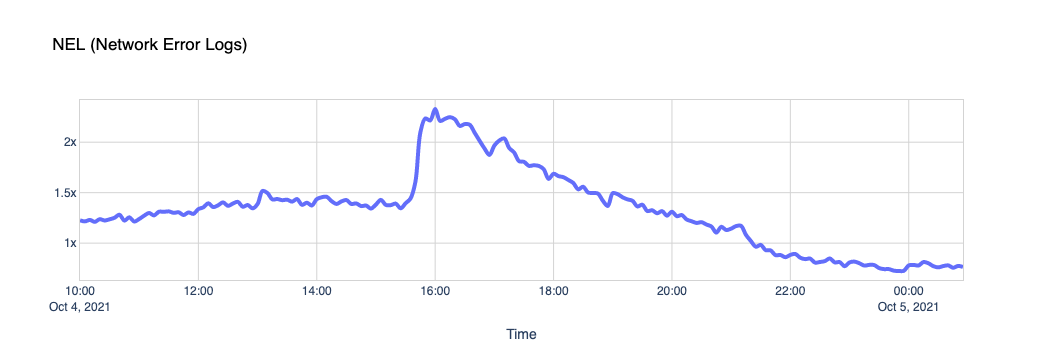
Network Error Logs
Network Error Logging, NEL for short, is an experimental technology supported in Chrome. A website can issue a Report-To header and ask the browser to send reports about network problems, like bad requests or DNS issues, to a specific endpoint.
Cloudflare uses NEL data to quickly help triage end-user connectivity issues when end-users reach our network. You can learn more about this feature in our help center.
If Facebook is down and their DNS isn’t responding, Chrome will start reporting NEL events every time one of the pages in our zones fails to load Facebook comments, posts, ads, or authentication buttons. This chart shows it clearly.
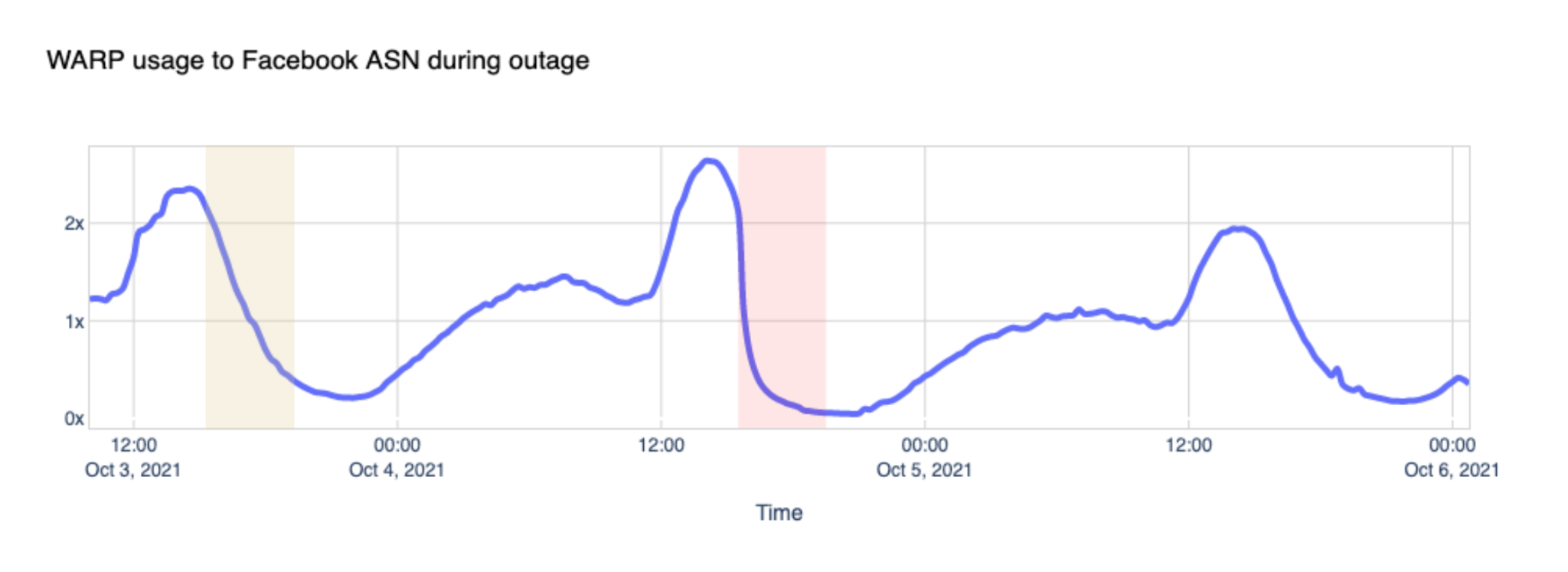
WARP
Cloudflare announced WARP in 2019, and called it “A VPN for People Who Don’t Know What V.P.N. Stands For” and offered it for free to its customers. Today WARP is used by millions of people worldwide to securely and privately access the Internet on their desktop and mobile devices. Here’s what we saw during the outage by looking at traffic volume between WARP and Facebook’s network:
You can see how the steep drop in Facebook ASN traffic coincides with the start of the incident and how it compares to the same period the day before.
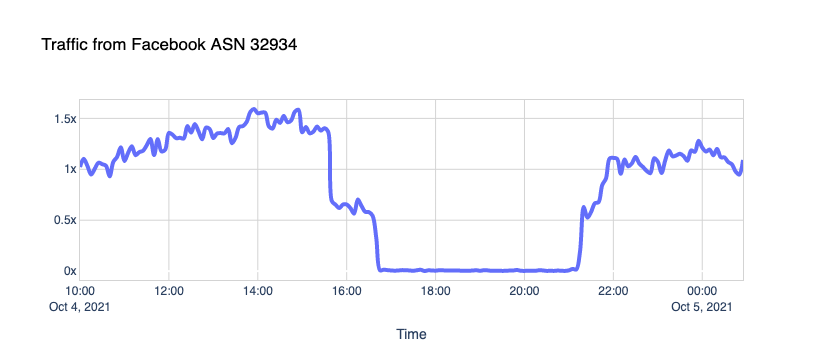
Our own traffic
People tend to think of Facebook as a place to visit. We log in, and we access Facebook, we post. It turns out that Facebook likes to visit us too, quite a lot. Like Google and other platforms, Facebook uses an army of crawlers to constantly check websites for data and updates. Those robots gather information about websites content, such as its titles, descriptions, thumbnail images, and metadata. You can learn more about this on the “The Facebook Crawler” page and the Open Graph website.
Here’s what we see when traffic is coming from the Facebook ASN, supposedly from crawlers, to our CDN sites:
The robots went silent.
What about the traffic coming to our CDN sites from Facebook User-Agents? The gap is indisputable.
We see about 30% of a typical request rate hitting us. But it’s not zero; why is that?
We’ll let you know a little secret. Never trust User-Agent information; it’s broken. User-Agent spoofing is everywhere. Browsers, apps, and other clients deliberately change the User-Agent string when they fetch pages from the Internet to hide, obtain access to certain features, or bypass paywalls (because pay-walled sites want sites like Facebook to index their content, so that then they get more traffic from links).
Fortunately, there are newer, more secure, and privacy-centric standards emerging like User-Agent Client Hints.
Core Web Vitals
Core Web Vitals are the subset of Web Vitals, an initiative by Google to provide a unified interface to measure real-world quality signals when a user visits a web page. Such signals include Largest Contentful Paint (LCP), First Input Delay (FID), and Cumulative Layout Shift (CLS).
Weuse Core Web Vitals with our privacy-centric Web Analytics product and collect anonymized data on how end-users experience the websites that enable this feature.
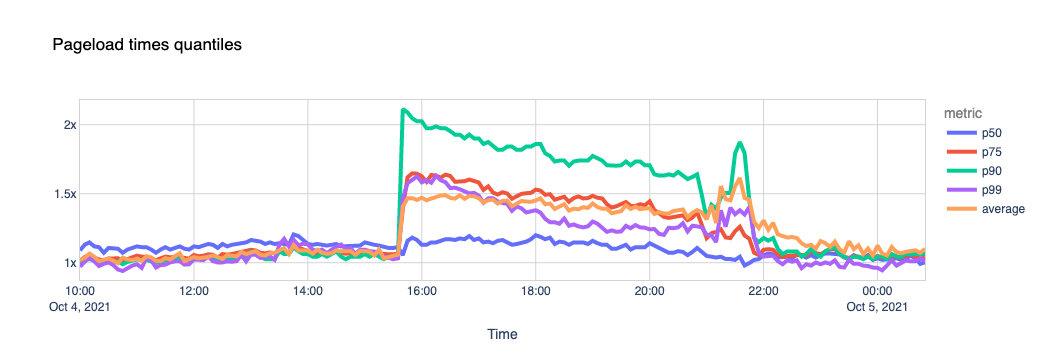
One of the metrics we can calculate using these signals is the page load time. Our theory is that if a page includes scripts coming from external sites (for example, Facebook “like” buttons, comments, ads), and they are unreachable, its total load time gets affected.
We used a list of about 400 domains that we know embed Facebook scripts in their pages and looked at the data.
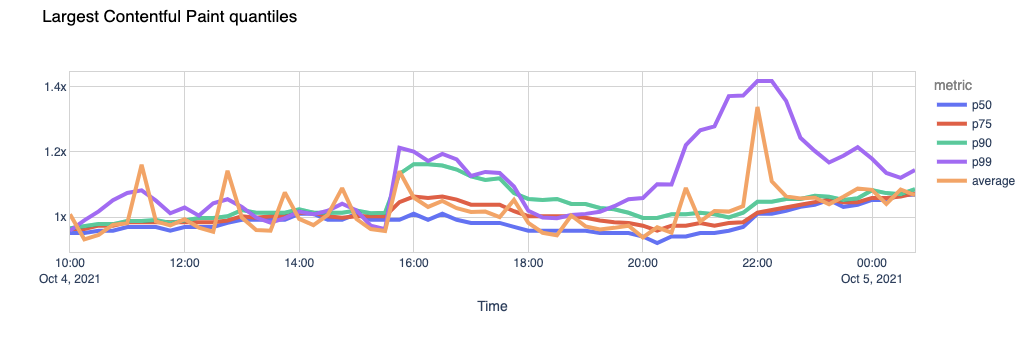
Now let’s look at the Largest Contentful Paint. LCP marks the point in the page load timeline when the page’s main content has likely loaded. The faster the LCP is, the better the end-user experience.
Again, the page load experience got visibly degraded.
The outcome seems clear. The sites that use Facebook scripts in their pages took 1.5x more time to load their pages during the outage, with some of them taking more than 2x the usual time. Facebook’s outage dragged the performance of some other sites down.
Conclusion
When Facebook, Instagram, and WhatsApp went down, the Web felt it. Some websites got slower or lost traffic, other services and platforms got unexpected load, and people lost the ability to communicate or do business normally.
The week of big Microsoft releases continues as the company brings Windows 365 Enterprise support for Windows 11. On Monday, Microsoft rolled out Windows 11 but the company is also announcing, “Windows 365 Enterprise supports Windows 11 for all newly … Read more
The date of the next Wakefield Show has already been noted here in the RISCOSitory bunker, but it has now been formally announced. As reported in that post, the event… Read more »
Before the update, all VMs hosted by Azure Virtual Desktop needed to be joined to a Windows Server AD domain, whether it be a domain hosted in Azure AD Domain Services or a domain hosted by domain controllers running in virtual machines.
The new Azure AD support works with personal desktops that have local user profiles; pooled desktops used as a jump box, providing that data isn’t saved on the VM used as a jump box; and pooled desktops or apps where users don’t need to save data on the VM.
But before you start cheering, there are several limitations that Microsoft lays out in its documentation here, including:
Azure AD-joined VMs only supports local user profiles currently.
Azure AD-joined VMs can’t access Azure Files file shares for FSLogix or MSIX app attach. You’ll need Kerberos authentication to access either of these features.
The Windows Store client doesn’t currently support Azure AD-joined VMs.
Azure Virtual Desktop doesn’t currently support single sign-on for Azure AD-joined VMs.
Windows 365 vs Azure Virtual Desktop
Windows 365 Cloud PC provides a similar service to Azure Virtual Desktop but there are some key differences. Windows 365 is priced per user for a month, but Azure Virtual Desktop pricing is based on how much a VM is used. Windows 365 makes it simpler for organizations to deploy VMs to users without having to maintain a virtual desktop infrastructure (VDI) either on-premises or in the cloud.
Azure Virtual Desktop uses a multisession version of Windows 10, and soon Windows 11. But Windows 365 dedicates a VM to each user and it allows organizations to purchase the service much in the same way they might buy a license for a Microsoft 365 solution, like Exchange Online.
For a complete rundown of the differences between Windows 365 and Azure Virtual Desktop, check out Mary Jo Foley’s chat with Nerdio CEO, Vadim Vladimirskiy here.
New feature limitations could curb Azure Virtual Desktop’s viability with Azure AD-joined VMs
Azure AD-joined VM support is something that might simplify deployment of Azure Virtual Desktop for some organizations. But you should carefully consider your use case because there are quite a few limitations that could curb its viability.
Check out Microsoft’s documentation here for complete details about how to deploy Azure AD-joined VMs in Azure Virtual Desktop.
Depending on which platform you use, there may be a number of different options available to you for RISC OS itself. As well as the standard distribution from RISC OS… Read more »
[lexie] is a librarian, and librarians live in the real world. They’re not concerned with vague digital notions about the size of data, but practical notions of space. Thus, she created a tool to answer an important question: how long do your shelves need to be if you’re storing all your information on 3.5″ floppy disks?
It’s a great question, and one we find ourselves asking, well, pretty much never. [lexie]’s tool is also built using modern web technologies, and 3.5″ floppy disks were never really used for bulk storage, either. It just makes the whole thing all the more frivolous, and that makes it more fun.
You can key in any quantity from megabytes to exabytes and the tool will spit out the relevant answer in anything from millimeters to miles as appropriate. Despite the graphics on the web page, it does assume rational shelving practices of placing disks along the shelves on their thinner 4 mm edge.
We’d love to see a expanded version that covers other storage methods, like tape, hard drives, or burnt media. It could actually become pretty useful for those building their own mass storage farms at home. With CHIA cryptocurrency that could become more popular, even if it does run us all out of hard drives along the way. Altnernatively, you might consider hooking up a floppy controller for your Raspberry Pi.
🎉🤖 PRODUCT LAUNCH NEWS 🎉🤖 Launch of Skynet Homescreen! 🚀DeFi needs decentralized front-ends and we’re proud to launch the FIRST and ONLY dashboard for managing decentralized apps in one place in-browser.
With last year’s London Show becoming a virtual event because of the pandemic and associated restrictions, the RISC OS User Group of London (ROUGOL) has announced that this year’s event… Read more »
Cisco held a conference call for press and analysts last week to discuss changes and evolvements in the vendor’s Partner Experience Platform (PXP) and PX and CX Cloud, while also highlighting some key areas where partners are establishing growth.
On the call was SVP of global partner sales Oliver Tuszik, VP of partner performance Jose van Dijk and SVP of customer and partner experience engineering Tony Colon, who each shared their insights into the partner landscape at Cisco and the company’s key areas of focus and improvement moving forward.
That includes new functionalities in the PXP such as AI-infused sales and planning tools for partners and the planned full launch of PX Cloud – a platform which provides partners with information and insights about their customers.
Here are the three main areas Cisco’s channel bosses chose to focus on during the press and analyst roundtable event…
Partner influence growing
Sharing updates on how Cisco’s partners were performing, Tuszik said the company’s partners are “leading the shift to software” and are continuing to grow their own recurring revenue in the process.
“The indirect partner share keeps growing. Where people say it’s going more direct, more digital, we are seeing fact-based bookings where our indirect sales via our partners are getting an even bigger share,” he said.
Tuszik pointed to the rise in partners selling more adoption services and increasing renewals rates, citing research from the company which found those figures had risen by 33 per cent and 40 per cent year-on-year respectively.
He also claimed distribution has contributed more than 50 per cent to Cisco’s growth since FY2014 – admitting this figure had “surprised” him.
“Routes to market are the most important expansion we need to drive right now,” Tuszik added.
“Customers want to reduce complexity. They no longer want to build or manage something on their own, they want somebody to deliver it as a service.”
PXP developments
Cisco launched PXP a year ago as part of its drive to create a simplified partner programme which Tuszik said at the time would “serve partners in a more flexible and agile way than ever before”.
Providing an update on the progress of PXP, Van Dijk said Cisco is targeting retiring “50 per cent” of the 180 tools partners used prior to PXP’s launch, with the current figure standing at “around 32 per cent”.
She announced several developments to PXP – the first of which is the introduction of a feature called Clair (customer lens for actionable insights and recommendations), which uses “ML and AI developed in house by Cisco” and is “based on 10 years of customer data and customer buying habits”.
Van Dijk claimed the tool would help partners to target the best opportunities by “segments, renewal, enterprise categories and sales plays” as just a few examples, and announced that it will become available for all partners in the second half of this year.
Also being introduced is an Integrated Partner Plan (IPP) which Van Dijk described as “a globally consistent plan” which would create “better alignment between the Cisco partner teams as well as the partner executives”.
“We are going to make sure that there is ongoing performance rankings or smart goals and KPIs that leverage all of the data that we have in PXP,” she added.
Thirdly, Cisco have introduced new capabilities in its sales opportunities segment – formerly known as renewals – which “lets partners see what the top line opportunities are, across all the different sales margins, as well as the performance on self-service metrics”.
“That of course, immediately impacts rebates and goes straight into the bottom line of the partners. We’ve added booking benchmarking information so partners can understand how they’re performing, relative to the peer group,” Van Dijk explained.
“And then, of course, we’re adding a new programme and new metric benchmarking information to provide a better context for prioritisation and decision making for our partners as well.”
And finally, Cisco has expanded PXP’s collaboration features through Partner Connect – which matches partners together “to help uncover and develop new buying centres and create valuable connections”.
PX Cloud and CX Cloud
Cisco also provided a demo for its PX Cloud, which is currently operating under limited availability but is set to become available for all partners “around the time” of Partner Summit.
“The partner experience platform is a full-fledged house, and there’s multiple tenants within that house,” Colon explained.
“And so, what we have in one of those tenants, or one of those floors, is something that we call the partner experience cloud. This is where customers get access to the telemetry data at its core.”
The PX Cloud provides partners with access to key information about their Cisco customers, which Colon claimed would provide “the full feedback on what is relevant to them”.
Key features of the PX Cloud includes a single dashboard which “tracks offer engagement, customer portfolios and progress” and provides an “enhanced contract view to enable partners to identify expiring contracts and asset details”.
Cisco also claims the PX Cloud will “enable partners to quickly create targeted offers for specific customers” as well as “receive customer interests and feedback details”.
Meanwhile, the customer experience (CX) Cloud is the “close relative” of the PX Cloud and allows the customers of partners to view “telemetry data, assets, contracts and licences”.
Google Cloud’s Professional Services Organization (PSO) engages with customers to ensure effective and efficient operations in the cloud, from the time they begin considering how cloud can help them overcome their operational, business or technical challenges, to the time they’re looking to optimize their cloud workloads.
We know that all parts of the cloud journey are important and can be complex. In this blog post, we want to focus specifically on the migration process and how PSO engages in a myriad of activities to ensure a successful migration.
As a team of trusted technical advisors, PSO will approach migrations in three phases:
While this post will not cover in detail all of the steps required for a migration, it will focus on how PSO engages in specific activities to meet customer objectives, manage risk, and deliver value. We will discuss the assets, processes and tools that we leverage to ensure success.
Pre-Migration Planning
Assess Scope
Before the migration happens, you will need to understand and clarify the future state that you’re working towards. From a logistical perspective, PSO will be helping you with capacity planning to ensure sufficient resources are available for your envisioned future state.
While migration into the cloud does allow you to eliminate many of the considerations for the physical, logistical, and financial concerns of traditional data centers and co-locations, it does not remove the need for active management of quotas, preparation for large migrations, and forecasting. PSO will help you forecast your needs in advance and work with the capacity team to adjust quotas, manage resources, and ensure availability.
Once the future state has been determined, PSO will also work with the product teams to determine any gaps in functionality. PSO capturesfeature requests across Google Cloud services and makes sure they are understood, logged, tracked, and prioritized appropriately with the relevant product teams. From there, they work closely with the customer to determine any interim workarounds that can be leveraged while waiting for the feature to land, as well as providing updates on the upcoming roadmap.
Based on the scoping requirements and tooling available to assist in the migration, PSO will help recommend a migration approach. We understand that enterprises have specific needs; differing levels of complexity and scale; regulatory, operational, or organization challenges that will need to be factored into the migration. PSO will help customers think through the different migration options and how all of the considerations will play out.
PSO will work with the customer team to determine the best migration approach for moving servers from on-prem to Google Cloud. PSO will walk customers through different migration approaches, such as refactoring, lift-shift, or new installs. From there, the customer can determine the best fit for their migration. PSO will provide guidance on best practices and use cases from other customers with similar use cases.
Google offers a variety of cloud native tools that can assist with asset discovery, the migration itself, and post-migration optimization. PSO, as one example, will help work with project managers to determine the best tooling that accommodates the customer’s requirements for migrating servers. PSO will also engage Google product team to ensure the customer fully understands the capabilities of each tool and the best fit for the use case. Google understands from a tooling perspective, one size does not fit all, thus PSO will work with the customer on determining the best migration approach and tooling for different requirements.
Cutover Activities
Once all of the planning activities have been completed, PSO will assist in making sure the cutover is successful.
During and leading up to critical customer events, PSO can provide proactive event management services which deliver increased support and readiness for key workloads. Beyond having a solid architecture and infrastructure on the platform, support for this infrastructure is essential and TAMs will help ensure that there are additional resources to support and unblock the customer where challenges arise.
As part of event management activities, PSO liaises with the Google Cloud Support Organization to ensure quick remediation and high resilience for situations where challenges arise. A war room is usually created to facilitate quick communication about the critical activities and roadblocks that arise. These war rooms can give customers a direct line to the support and engineering teams that will triage and resolve their issues.
Post-Migration Activities
Once cutover is complete, PSO will continue to provide support in areas such incident management, capacity planning, continuous operational support, and optimization to ensure the customer is successful from start to finish.
PSO will serve as the liaison between the customer and Google engineers. If support cases need to be escalated, PSO will ensure the appropriate parties are involved and work to get the case resolved in a timely manner. Through operational rigor, PSO will work with the customer in determining if certain Google Cloud services will be beneficial to the customer objectives. If services will add value to the customer, PSO will help enable the services so it aligns with the customer’s goal and current cloud architecture. In cases where there are missing gaps in services, PSO will proactively work with the customer and Google engineering teams to close the gaps by enabling additional functionality in the services.
PSO will continue to work with the engineering teams to consistently review and provide recommendations on the customer’s cloud architecture in ensuring the most optimal and cost efficient design along with adhering to Google’s best practices guidelines.
Aside from migrations, PSO is also responsible for providing continuous training of Google Cloud to customers. To ensure consistent development of Google Cloud, PSO will work with the customer to jointly develop a learning roadmap to ensure the customer has the necessary skills to succeed in delivering successful projects in Google Cloud.
Conclusion
Google PSO will be actively engaged throughout the customer’s cloud journey to ensure the necessary guidance, methodology, and tools are presented to the customer. PSO will engage in a series of activities from pre-migration planning to post migration in key areas such as capacity planning to ensure sufficient resources are allocated for future workloads to providing support on technical cases for troubleshooting. PSO will serve as a long-term trusted advisor who will be the voice of the customer and provide the reliability and stability of the customer’s Google Cloud environment.
Storage capacity reservations for Azure Files enable you to significantly reduce the total cost of ownership of storage by pre-committing to storage utilization. To achieve the lowest costs in Azure, you should consider reserving capacity for all production workloads.
Over the years I’ve had a few friends and clients reach out to me, unhappy about some public cloud services being removed, either from a name-brand cloud provider or secondary players. At times, entire clouds were being shut down.
The cloud providers typically give plenty of notice (sometimes years), calling the service “legacy” or “classic” for a time. They’ll have a migration tool and procedures to move to other similar services, sometimes to competitors. In some cases, they will pay for consultants to do it for you.
As a tech CTO for many years, I also had to sunset parts or all of technologies we sold. This meant removing support and eventually making the technology no longer viable for the customer. Again, this was done with plenty of notice, providing migration tools and even funding to make the move to more modern and likely better solutions.
In today’s post, we’ll walk through how to easily create optimal machine learning models with BigQuery ML’s recently launched automated hyperparameter tuning. You can also register for our free training on August 19 to gain more experience with hyperparameter tuning and get your questions answered by Google experts. Can’t attend the training live? You can watch it on-demand after August 19.
Without this feature, users have to manually tune hyperparameters by running multiple training jobs and comparing the results. The efforts might not even work without knowing the good candidates to try out.
With a single extra line of SQL code, users can tune a model and have BigQuery ML automatically find the optimal hyperparameters. This enables data scientists to spend less time manually iterating hyperparameters and more time focusing on unlocking insights from data. This hyperparameter tuning feature is made possible in BigQuery ML by using Vertex Vizier behind-the-scenes. Vizier was created by Google research and is commonly used for hyperparameter tuning at Google.
Optimizing model performance with one extra line of code to automatically tune hyperparameters, as well as customizing the search space
Reducing manual time spent trying out different hyperparameters
Leveraging transfer learning from past hyperparameter-tuned models to improve convergence of new models
How do you create a model using Hyperparameter Tuning?
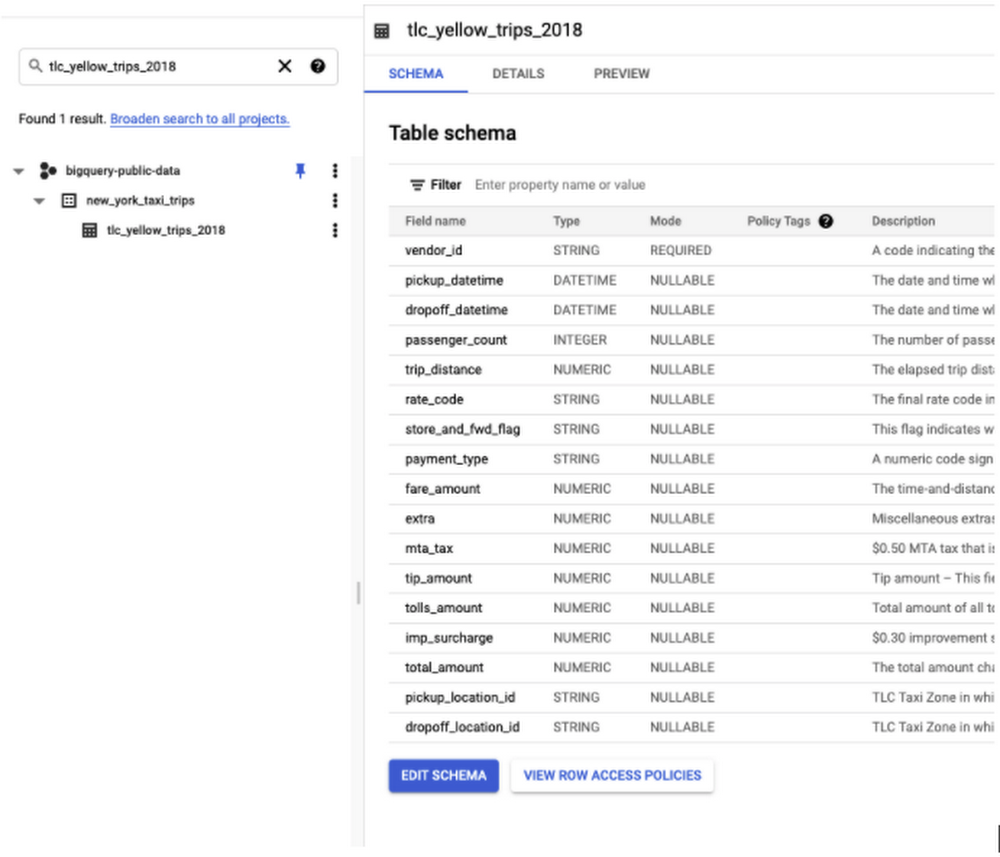
You can follow along in the code below by first bringing the relevant data to your BigQuery project. We’ll be using the first 100K rows of data from New York taxi trips that is part of the BigQuery public datasets to predict the tip amount based on various features, as shown in the schema below:
First create a dataset, bqml_tutorial in the United States (US) multiregional location, then run:
Without hyperparameter tuning, the model below uses the default hyperparameters, which may very likely not be ideal. The responsibility falls on data scientists to train multiple models with different hyperparameters, and compare evaluation metrics across all the models. This can be a time-consuming process and it can become difficult to manage all the models. In the example below, you can train a linear regression model, using the default hyperparameters, to try to predict taxi fares.
With hyperparameter tuning (triggered by specifying NUM_TRIALS), BigQuery ML will automatically try to optimize the relevant hyperparameters across a user-specified number of trials (NUM_TRIALS). The hyperparameters that it will try to tune can be found in this helpful chart.
In the example above, with NUM_TRIALS=20, starting with the default hyperparameters, BigQuery ML will try to train model after model while intelligently using different hyperparameter values — in this case, l1_reg and l2_reg as described here. Before training begins, the dataset will be split into three parts1: training/evaluation/test. The trial hyperparameter suggestions are calculated based upon the evaluation data metrics. At the end of each trial training, the test set is used to evaluate the trial and record its metrics in the model. Using an unseen test set ensures the objectivity of the test metric reported at the end of tuning.
The dataset is split into 3-ways by default when hyperparameter tuning is enabled. The user can choose to split the data in other ways as described in the documentation here.
We also set max_parallel_trials=2 in order to accelerate the tuning process. With 2 parallel trials running at any time, the whole tuning should take roughly as long as 10 serial training jobs instead of 20.
Inspecting the trials
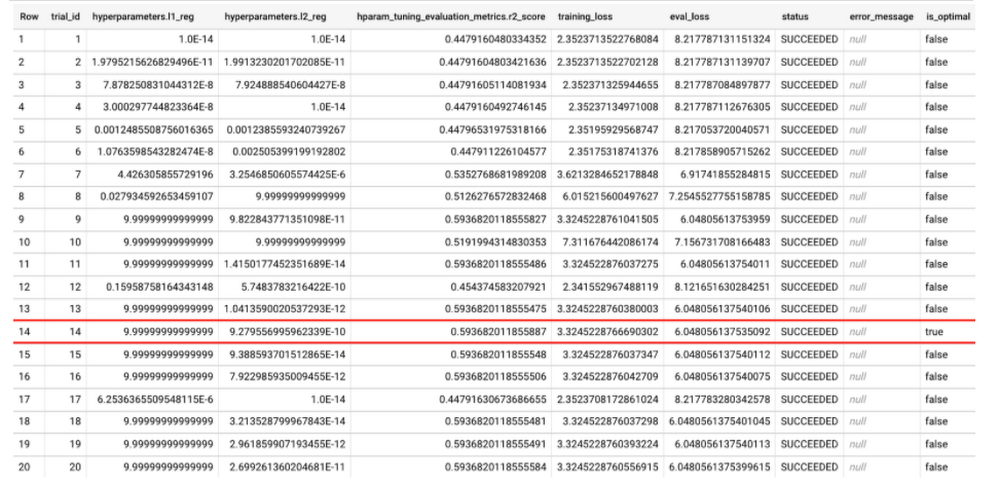
How do you inspect the exact hyperparameters used at each trial? You can use ML.TRIAL_INFO to inspect each of the trials when training a model with hyperparameter tuning.
Tip: You can use ML.TRIAL_INFO even while your models are still training.
In the screenshot above, ML.TRIAL_INFO shows one trial per row, with the exact hyperparameter values used in each trial. The results of the query above indicate that the 14th trial is the optimal trial, as indicated by the is_optimal column. Trial 14 is optimal here because the hparam_tuning_evaluation_metrics.r2_score — which is R2 score for the evaluation set — is the highest. The R2 score improved impressively from 0.448 to 0.593 with hyperparameter tuning!
Note that this model’s hyperparameters were tuned just by using num_trials and max_parallel_trials, and BigQuery ML searches through the default hyperparameters and default search spaces as described in the documentation here. When default hyperparameter search spaces are used to train the model, the first trial (TRIAL_ID=1) will always use default values for each of the default hyperparameters for the model type LINEAR_REG. This is to help ensure that the overall performance of the model is no worse than a non-hyperparameter tuned model.
Evaluating your model
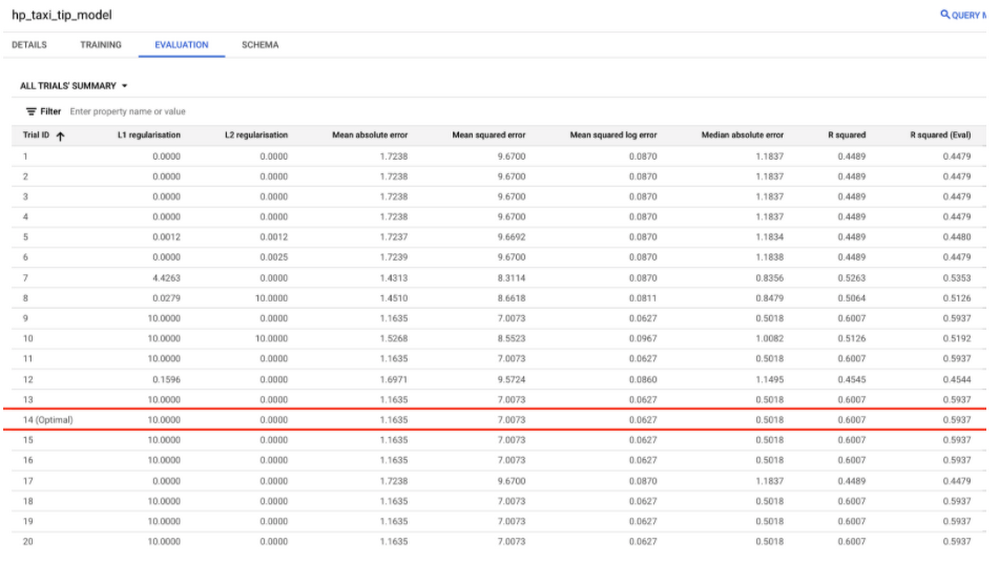
How well does each trial perform on the test set? You can use ML.EVALUATE, which returns a row for every trial along with the corresponding evaluation metrics for that model.
In the screenshot above, the columns “R squared” and “R squared (Eval)” correspond to the evaluation metrics for the test and evaluation set, respectively. For more details, see the data split documentation here.
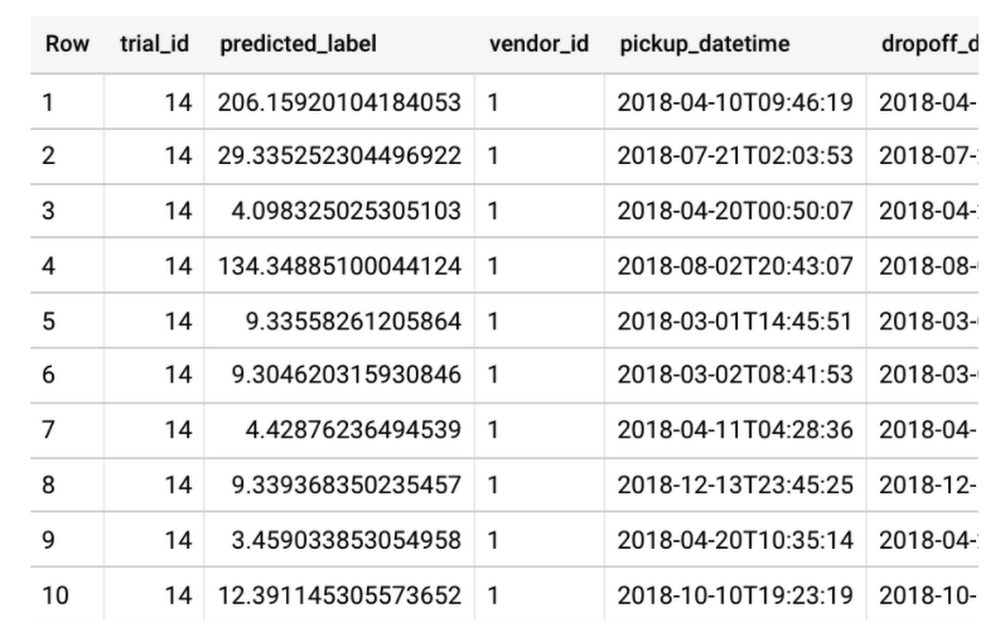
Making predictions with your hyperparameter-tuned model
How does BigQuery ML select which trial to use to make predictions? ML.PREDICT will use the optimal trial by default and also returns which trial_id was used to make the prediction. You can also specify which trial to use by following the instructions.
Customizing the search space
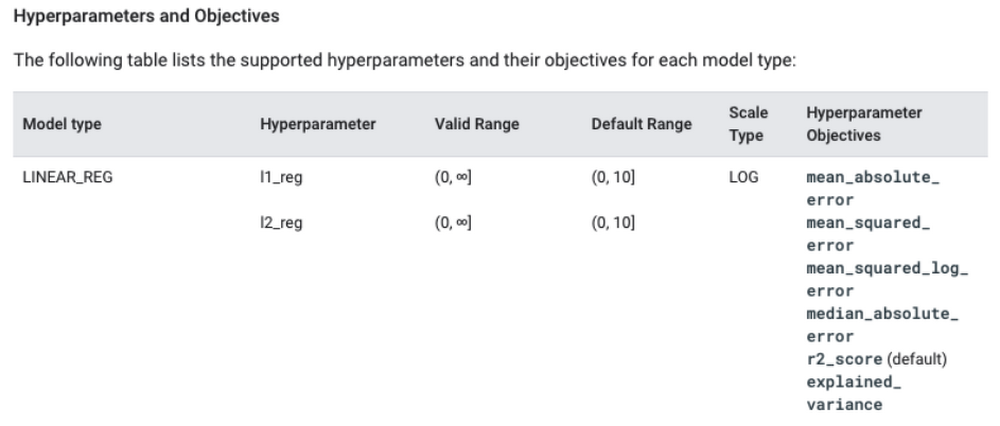
There may be times where you want to select certain hyperparameters to optimize or change the default search space per hyperparameter. To find the default range for each hyperparameter, you can explore the Hyperparameters and Objectives section of the documentation.
For LINEAR_REG, you can see the feasible range for each hyperparameter. Using the documentation as reference, you can create your own customized CREATE MODEL statement:
Transfer learning from previous runs
If this isn’t enough, hyperparameter tuning in BigQuery with Vertex Vizier running behind the scenes means you also get the added benefit of transfer learning between models that you train, as described here.
How many trials do I need to tune a model?
The rule of thumb is at least 10 * the number of hyperparameters, as described here (assuming no parallel trials). For example, LINEAR_REG will tune 2 hyperparameters by default, and so we recommend using NUM_TRIALS=20.
Pricing
The cost of hyperparameter tuning training is the sum of all executed trials costs, which means that if you train a model with 20 trials, the billing would be equal to the total cost across all 20 trials. The pricing of each trial is consistent with the existing BigQuery ML pricing model.
Note: Please be aware that the costs are likely going to be much higher than training one model at a time.
Exporting hyperparameter-tuned models out of BigQuery ML
If you’re looking to use your hyperparameter-tuned model outside of BigQuery, you can export your model to Google Cloud Storage, which you can then use to, for example, host in a Vertex AI Endpoint for online predictions.
Summary
With automated hyperparameter tuning in BigQuery ML, it’s as simple as adding one extra line of code (NUM_TRIALS) to easily improve model performance! Ready to get more experience with hyperparameter tuning or have questions you’d like to ask? Sign up here for our no-cost August 19 training.
In the crowd of GNU/Linux and BSD users that throng our community, it’s easy to forget that those two families are not the only games in the open-source operating system town. One we’ve casually kept an eye on for years is ReactOS, the long-running open-source Windows-compatible operating system that is doing its best to reach a stable Windows XP-like experience. Their most recent update has a few significant advances mentioned in it that hold the promise of it moving from curiosity to contender, so is definitely worth a second look.
ReactOS has had 64-bit builds for a long time now, but it appears they’ve made some strides in both making them a lot more stable, and moving away from the MSVC compiler to GCC. Sadly this doesn’t seem to mean that this now does the job of a 64-bit Windows API, but it should at least take advantage internally of the 64-bit processors. In addition they have updated their support for the Intel APIC that is paving the way for ongoing work on multiprocessor support where their previous APIC driver couldn’t escape the single processor constraint of an original Intel 8259.
Aside from these its new-found support for multiple monitors should delight more productive users, and its improved support for ISA plug-and-play cards will be of interest to retro enthusiasts.
We took a close look at the current ReactOS release when it came out last year, and concluded that its niche lay in becoming a supported and secure replacement for the many legacy Windows XP machines that are still hanging on years after that OS faded away. We look forward to these and other enhancements in their next release, which can’t be far away.
The content below is taken from the original ( Zero trust with reverse proxy), to continue reading please visit the site. Remember to respect the Author & Copyright.
A reverse proxy stands in front of your data, services, or virtual machines, catching requests from anywhere in the world and carefully checking each one to see if it is allowed.
In order to decide (yes or no) the proxy will look at who and what.
Who are you (the individual making the request)? What is your role? Do you have access permission (authorization)?
What device are you using to make the request? How healthy is your device right now? Where are you located?
At what time are you making the request?
This issue of GCP Comics presents an example of accessing some rather confidential data from an airplane, and uses that airplane as a metaphor to explain what the proxy is doing.
Click to enlarge
Reverse proxies work as part of the load balancing step when requests are made to web apps or services, and they can be thought of as another element of the network infrastructure that helps route requests to the right place. No one can access your resources unless they meet certain rules and conditions.
If a request is invalid or doesn’t meet the necessary criteria set by your administrators, either because it is from an unauthorized person or an unsafe device, then the proxy will deny the request.
Why might the proxy say no to my request? When assessing the user making the request, denial of access could be due to reasons such as:
I’m in Engineering, but I am trying to access Finance data.
I’m not even a part of the company.
My job changed, and I lost access.
Looking at the device originating the request, the proxy could deny access due to a number of factors, such as:
Device operating system out of date
Malware detected
Device is not reporting in
Disk encryption missing
Device doesn’t have screen lock
Leveraging identity and device information to secure access to your organization’s resources improves your security posture.
Resources
To learn more about proxies and Zero Trust, check out the following resources:
Hi, I have done some components for PowerShell Universal that are mostly doing things on remote Windows Clients. It’s perfect if you want to add them to your support page or similar for the IT-Support.
I’m working to do my AD stuff universal also and ofc add some more things to this Repo.
Anyway I just want to share and if you want to use it feel free to do so, if you want to make some PR etc. you can also do that 🙂
I’ve created a project where you can create all the free resources available from the major cloud providers in a single command. I used it as a way to learn infrastructure as a code without relying on companies or external training, and without spending fortunes as well. Furthermore, I hope it helps you, as it did for me.
You are welcome to contribute and ask questions, it is not finished by any means, so be aware you must learn the basics before messing with its configurations.
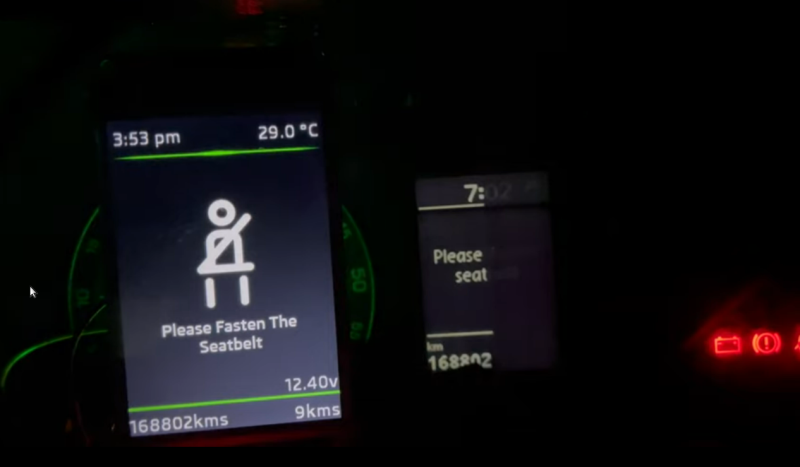
All of the technological improvements to vehicles over the past few decades have led to cars and trucks that would seem borderline magical to anyone driving something like a Ford Pinto in the 1970s. Not only are cars much safer due to things like crumple zones, anti-lock brakes, air bags, and compulsory seat belt use, but there’s a wide array of sensors, user interfaces, and computers that also improve the driving experience. At least, until it starts wearing out. The electronic technology in our modern cars can be tricky to replace, but [Aravind] at least was able to replace part of the instrument cluster on his aging (yet still modern) Skoda and improve upon it in the process.
These cars have a recurring problem with the central part of the cluster that includes an LCD display. If replacement parts can even be found, they tend to cost a significant fraction of the value of the car, making them uneconomical for most. [Aravind] found that a 3.5″ color LCD that was already available fit perfectly in the space once the old screen was removed, so from there the next steps were to interface it to the car. These have a CAN bus separated from the main control CAN bus, and the port was easily accessible, so an Arduino with a RTC was obtained to handle the heavy lifting of interfacing with it.
Now, [Aravind] has a new LCD screen in the console that’s fully programmable and potentially longer-lasting than the factory LCD was. There’s also full documentation of the process on the project page as well, for anyone else with a Volkswagen-adjacent car from this era. Either way, it’s a much more economical approach to replacing the module than shelling out the enormous cost of OEM replacement parts. Of course, CAN bus hacks like these are often gateway projects to doing more involved CAN bus projects like turning an entire vehicle into a video game controller.
We tried ’em on Windows, iOS and Android, and can’t say they’re very exciting
First Look Microsoft has revealed the full range of options and pricing for its Windows 365 Cloud PCs, and The Register is not impressed – on price or performance.…