Josh Nussbaum
Contributor
Joshua Nussbaum is a partner at the New York-based venture firm, Compound.
Blockchain technology, cryptocurrencies, and token sales are all the rage right now. In the 5+ years I’ve been working in the VC industry, this is by and large the fastest I’ve seen any area of technology take off in terms of new company (or project) formation.
It wasn’t too long ago that founders and VCs were mainly focused on centralized exchanges, enterprise or private blockchain solutions, wallets, amongst several other popular blockchain startup ideas that dominated the market from 2012 to somewhere around 2016.
However, as I wrote about a few months ago, the rise of Ethereum with its Turing-complete scripting language and the ability for developers to include state in each block, has paved the way for smart contract development. This has led to an influx of teams building decentralized projects seeking to take advantage of the most valuable property of blockchains — the ability to reach a shared truth that everyone agrees on without intermediaries or a centralized authority.
There are many exciting developments coming to market both in terms of improving existing blockchain functionality as well as the consumer’s experience. However, given the rapid pace at which projects are coming to market, I’ve found it to be difficult to keep track of each and every project and where each one fits into the ecosystem.
Furthermore, it’s easy to miss the forest for the trees without a comprehensive view of what the proverbial forest looks like.
As a result, here’s a compiled a list of all of the decentralized blockchain-based projects that I have been following, and was able to dig up through research, along with recommendations from friends in the ecosystem.
A quick disclaimer: While it’s difficult to pigeonhole a number of projects into one category, I did my best to pinpoint the main purpose or value proposition of each project and categorize them as such. There are certainly many projects that fall into the gray area and could fit into multiple categories. The hardest ones are the “fat protocols” which offer functionality in more than a couple of areas.
Below is an overview of each broader category I’ve identified, touching on some of the subcategories that comprise them:
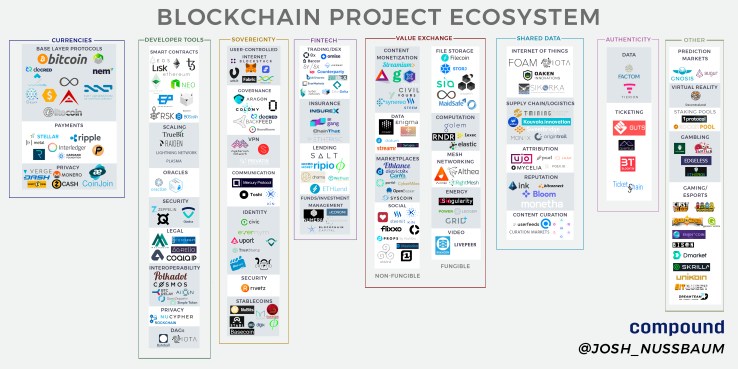
Currencies
 For the most part, these projects were created with the intention of building a better currency for various use cases and represent either a store of value, medium of exchange, or a unit of account.
For the most part, these projects were created with the intention of building a better currency for various use cases and represent either a store of value, medium of exchange, or a unit of account.
While Bitcoin was the first and is the most prominent project in the category, many of the other projects set out to improve upon a certain aspect of Bitcoin’s protocol or tailor it towards a specific use case.
The Privacy subcategory could probably fall into either the Payments or Base Layer Protocols categories, but I decided to break them out separately given how important anonymous, untraceable cryptocurrencies (especially Monero and ZCash) are for users who would like to conceal a transaction because they prefer not to broadcast a certain purchase for one reason or another, or for enterprises who don’t want to reveal trade secrets.
Developer Tools
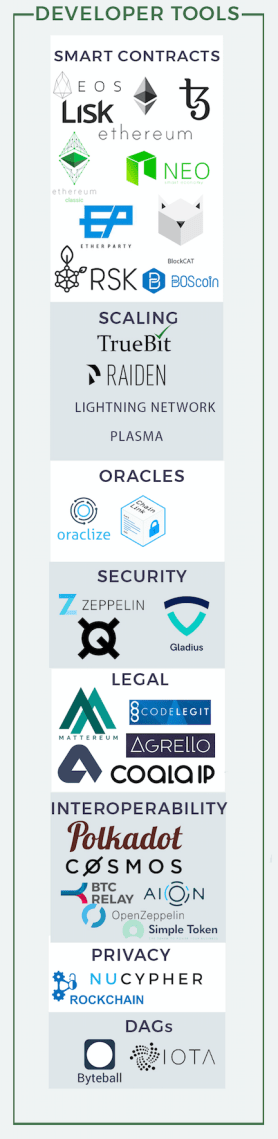
Projects within this category are primarily used by developers as the building blocks for decentralized applications. In order to allow users to directly interact with protocols through application interfaces (for use cases other than financial ones), many of the current designs that lie here need to be proven out at scale.
Protocol designs around scaling and interoperability are active areas of research that will be important parts of the Web3 development stack.
In my opinion, this is one of the more interesting categories at the moment from both an intellectual curiosity and an investment standpoint.
In order for many of the blockchain use cases we’ve been promised to come to fruition such as fully decentralized autonomous organizations or a Facebook alternative where users have control of their own data, foundational, scalable infrastructure needs to grow and mature.
Many of these projects aim at doing just that.
Furthermore, these projects aren’t in a “winner take all” area in the same way that say a cryptocurrency might be as a store of value.
For example, building a decentralized data marketplace could require a a number of Developer Tools subcategories such as Ethereum for smart contracts, Truebit for faster computation, NuCypherfor proxy re-encryption,ZeppelinOS for security, and Mattereum for legal contract execution to ensure protection in the case of a dispute.
Because these are protocols and not centralized data silos, they can talk to one another, and this interoperability enables new use cases to emerge through the sharing of data and functionality from multiple protocols in a single application.
Preethi Kasireddy does a great job of explaining this dynamic here.
Fintech

This category is fairly straightforward. When you’re interacting with a number of different protocols and applications (such as in the Developer Tools example above), many may have their own native cryptocurrency, and thus a number of new economies emerge.
In any economy with multiple currencies, there’s a need for tools for exchanging one unit of currency for another, facilitating lending, accepting investment, etc.
The Decentralized Exchanges (DEX) subcategory could arguably have been categorized as Developer Tools.
Many projects are already starting to integrate the 0x protocol and I anticipate this trend to continue in the near future. In a world with the potential for an exorbitant number of tokens, widespread adoption of applications using several tokens will only be possible if the complexity of using them is abstracted away — a benefit provided by decentralized exchanges.
Both the Lending and Insurance subcategories benefit from economies of scale through risk aggregation.
By opening up these markets and allowing people to now be priced in larger pools or on a differentiated, individual basis (depending on their risk profile), costs can decrease and therefore consumers should in theory win.
Blockchains are both stateful and immutable so because previous interactions are stored on chain, users can be confident that the data that comprises their individual history hasn’t been tampered with.
Sovereignty

As the team at Blockstack describes in their white paper:
“Over the last decade, we’ve seen a shift from desktop apps (that run locally) to cloud-based apps that store user data on remote servers. These centralized services are a prime target for hackers and frequently get hacked.”
Sovereignty is another area that I find most interesting at the moment.
While blockchains still suffer from scalability and performance issues, the value provided by their trustless architecture can supersede performance issues when dealing with sensitive data; the safekeeping of which we’re forced to rely on third parties for today.
Through cryptoeconomics, users don’t need to trust in any individual or organization but rather in the theory that humans will behave rationally when correctly incentivized.
The projects in this category provide the functionality necessary for a world where users aren’t forced to trust in any individual or organization but rather in the incentives implemented through cryptography and economics.
Value Exchange
A key design of the Bitcoin protocol is the ability to have trust amongst several different parties, despite there being no relationship or trust between those parties outside of the blockchain. Transactions can be created and data shared by various parties in an immutable fashion.
It’s widely considered fact that people begin to organize into firms when the cost of coordinating production through a market is greater than within a firm individually.
But what if people could organize into this proverbial “firm” without having to trust one another?
Through blockchains and cryptoeconomics, the time and complexity of developing trust is abstracted away, which allows a large number people to collaborate and share in the profits of such collaboration without a hierarchical structure of a traditional firm.
Today, middlemen and rent seekers are a necessary evil in order to keep order, maintain safety, and enforce the rules of P2P marketplaces. But in many areas, these cryptoeconomic systems can replace that trust, and cutting out middlemen and their fees will allow users to exchange goods and services at a significantly lower cost.

The projects in the subcategories can be broken down into two main groups: fungible and non-fungible. Markets that allow users to exchange goods and services that are fungible will commoditize things like storage, computation, internet connectivity, bandwidth, energy, etc. Companies that sell these products today compete on economies of scale which can only be displaced by better economies of scale.
By opening up latent supply and allowing anyone to join the network (which will become easier through projects like 1Protocol) this no longer becomes a daunting task, once again collapsing margins towards zero.
Non-fungible markets don’t have the same benefits although they still allow providers to earn what their good or service is actually worth rather than what the middlemen thinks it’s worth after they take their cut.
Shared Data
One way to think about the shared data layer model is to look at the airline industry’s Global Distribution Systems (GDS’s). GDS’s are a centralized data warehouse where all of the airlines push their inventory data in order to best coordinate all supply information, including routes and pricing.

This allows aggregators like Kayak and other companies in the space to displace traditional travel agents by building a front end on top of these systems that users can transact on.
Typically, markets that have been most attractive for intermediary aggregators are those in which there is a significant barrier to entry in competing directly, but whereby technological advances have created a catalyst for an intermediary to aggregate incumbents, related metadata, and consumer preferences (as was the case with GDS’s).
Through financial incentives provided by blockchain based projects, we’re witnessing the single most impactful technological catalyst which will open up numerous markets, except the value no longer will accrue to the aggregator but rather to the individuals and companies that are providing the data.
In 2015, Hunter Walk wrote that one of the biggest missed opportunities of the last decade was eBay’s failure to open up their reputation system to third parties which would’ve put them at the center of P2P commerce.
I’d even take this a step further and argue that eBay’s single most valuable asset is reputation data which is built up over long periods of time, forcing user lock-in and granting eBay the power to levy high taxes on its users for the peace of mind that they are transacting with good actors. In shared data blockchain protocols, users can take these types of datasets with them as other applications hook into shared data protocols, reducing barriers to entry; increasing competition and as a result ultimately increasing the pace of innovation.
The other way to think about shared data protocols can be best described using a centralized company, such as Premise Data, as an example. Premise Data deploys network contributors who collect data from 30+ countries on everything from specific food/beverage consumption to materials used in a specific geography.
The company uses machine learning to extract insights and then sells these datasets to a range of customers. Rather than finding and hiring people to collect these datasets, a project could be started that allows anyone to collect and share this data, annotate the data, and build different models to extract insights from the data.
Contributors could earn tokens which would increase in value as companies use the tokens to purchase the network’s datasets and insights. In theory, the result would be more contributors and higher quality datasets as the market sets the going rate for information and compensates participants accordingly relative to their contribution.
There are many similar possibilities as the “open data platform” has been a popular startup idea for a few years now with several companies finding great success with the model. The challenge I foresee will be in sales and business development.
Most of these companies sell their dataset to larger organizations and it will be interesting to see how decentralized projects distribute theirs in the future. There are also opportunities that weren’t previously possible or profitable as a standalone, private organization to pursue, given that the economics don’t work for a private company.
 Authenticity
Authenticity
Ultimately, cryptocurrencies are just digital assets native to a specific blockchain and projects in this category are using these digital assets to represent either real world goods (like fair tickets) or data.
The immutability of public blockchains allows network participants to be confident in the fact that the data written to them hasn’t been tampered with or changed in any way and that it will be available and accessible far into the future.
Hence why, for sensitive data or markets for goods which have traditionally been rife with fraud, it would make sense to use a blockchain to assure the user of their integrity.
Takeaways
While there’s a lot of innovation happening across all of these categories, the projects just getting started that I’m most excited about are enabling the web3 development stack by providing functionality that’s necessary across different use cases, sovereignty through user access control of their data, as well as fungible value exchange.
Given that beyond financial speculation we’ve yet to see mainstream cryptocurrency use cases, infrastructure development and use cases that are vastly superior for users in either cost, privacy, and/or security in extremely delicate areas (such as identity, credit scoring, VPN’s amongst others) seem to be the most likely candidates to capture significant value.
Longer-term, I‘m excited about projects enabling entire ecosystems to benefit from shared data and the bootstrapping of networks (non-fungible value exchange). I’m quite sure there are several other areas that I’m not looking at correctly or haven’t been dreamt up yet!
As always if you’re building something that fits these criterion or have any comments, questions or points of contention, I’d love to hear from you.
Thank you to Jesse Walden, Larry Sukernik, Brendan Bernstein, Kevin Kwok, Mike Dempsey, Julian Moncada, Jake Perlman-Garr, Angela Tran Kingyensand Mike Karnjanaprakorn for all your help on the market map and blog post.
Disclaimer: Compound is an investor in Blockstack and two other projects mentioned in this post which have not yet been announced.
*This article first appeared on Medium and has been republished courtesy of Josh Nussbaum.




