The content below is taken from the original ( Advancing the outage experience—automation, communication, and transparency), to continue reading please visit the site. Remember to respect the Author & Copyright.
“Service incidents like outages are an unfortunate inevitability of the technology industry. Of course, we are constantly improving the reliability of the Microsoft Azure cloud platform. We meet and exceed our Service Level Agreements (SLAs) for the vast majority of customers and continue to invest in evolving tools and training that make it easy for you to design and operate mission-critical systems with confidence.
In spite of these efforts, we acknowledge the unfortunate reality that—given the scale of our operations and the pace of change—we will never be able to avoid outages entirely. During these times we endeavor to be as open and transparent as possible to ensure that all impacted customers and partners understand what’s happening. As part of our Advancing Reliability blog series, series, I asked Sami Kubba, Principal Program Manager overseeing our outage communications process, to outline the investments we’re making to continue improving this experience.”—Mark Russinovich, CTO, Azure
In the cloud industry, we have a commitment to bring our customers the latest technology at scale, keeping customers and our platform secure, and ensuring that our customer experience is always optimal. For this to happen Azure is subject to a significant amount of change—and in rare circumstances, it is this change that can bring about unintended impact for our customers. As previously mentioned in this series of blog posts we take change very seriously and ensure that we have a systematic and phased approach to implementing changes as carefully as possible.
We continue to identify the inherent (and sometimes subtle) imperfections in the complex ways that our architectural designs, operational processes, hardware issues, software flaws, and human factors can align to cause service incidents—also known as outages. The reality of our industry is that impact caused by change is an intrinsic problem. When we think about outage communications we tend not to think of our competition as being other cloud providers, but rather the on-premises environment. On-premises change windows are controlled by administrators. They choose the best time to invoke any change, manage and monitor the risks, and roll it back if failures are observed.
Similarly, when an outage occurs in an on-premises environment, customers and users feel that they are more ‘in the know.’ Leadership is promptly made fully aware of the outage, they get access to support for troubleshooting, and expect that their team or partner company would be in a position to provide a full Post Incident Report (PIR)—previously called Root Cause Analysis (RCA)—once the issue is understood. Although our data analysis supports the hypothesis that time to mitigate an incident is faster in the cloud than on-premises, cloud outages can feel more stressful for customers when it comes to understanding the issue and what they can do about it.
Introducing our communications principles
During cloud outages, some customers have historically reported feeling as though they’re not promptly informed, or that they miss necessary updates and therefore lack a full understanding of what happened and what is being done to prevent future issues occurring. Based on these perceptions, we now operate by five pillars that guide our communications strategy—all of which have influenced our Azure Service Health experience in the Azure portal and include:
- Speed
- Granularity
- Discoverability
- Parity
- Transparency
Speed
We must notify impacted customers as quickly as possible. This is our key objective around outage communications. Our goal is to notify all impacted Azure subscriptions within 15 minutes of an outage. We know that we can’t achieve this with human beings alone. By the time an engineer is engaged to investigate a monitoring alert to confirm impact (let alone engaging the right engineers to mitigate it, in what can be a complicated array of interconnectivities including third-party dependencies) too much time has passed. Any delay in communications leaves customers asking, “Is it me or is it Azure?” Customers can then spend needless time troubleshooting their own environments. Conversely, if we decide to err on the side of caution and communicate every time we suspect any potential customer impact, our customers could receive too many false positives. More importantly, if they are having an issue with their own environment, they could easily attribute these unrelated issues to a false alarm being sent by the platform. It is critical that we make investments that enable our communications to be both fast and accurate.
Last month, we outlined our continued investment in advancing Azure service quality with artificial intelligence: AIOps. This includes working towards improving automatic detection, engagement, and mitigation of cloud outages. Elements of this broader AIOps program are already being used in production to notify customers of outages that may be impacting their resources. These automatic notifications represented more than half of our outage communications in the last quarter. For many Azure services, automatic notifications are being sent in less than 10 minutes to impacted customers via Service Health—to be accessed in the Azure portal, or to trigger Service Health alerts that have been configured, more on this below.
With our investment in this area already improving the customer experience, we will continue to expand the scenarios in which we can notify customers in less than 15 minutes from the impact start time, all without the need for humans to confirm customer impact. We are also in the early stages of expanding our use of AI-based operations to identify related impacted services automatically and, upon mitigation, send resolution communications (for supported scenarios) as quickly as possible.
Granularity
We understand that when an outage causes impact, customers need to understand exactly which of their resources are impacted. One of the key building blocks in getting the health of specific resources are Resource Health signals. The Resource Health signal will check if a resource, such as a virtual machine (VM), SQL database, or storage account, is in a healthy state. Customers can also create Resource Health alerts, which leverage Azure Monitor, to let the right people know if a particular resource is having issues, regardless of whether it is a platform-wide issue or not. This is important to note: a Resource Health alert can be triggered due to a resource becoming unhealthy (for example, if the VM is rebooted from within the guest) which is not necessarily related to a platform event, like an outage. Customers can see the associated Resource Health checks, arranged by resource type.
We are building on this technology to augment and correlate each customer resource(s) that has moved into an unhealthy state with platform outages, all within Service Health. We are also investigating how we can include the impacted resources in our communication payloads, so that customers won’t necessarily need to sign in to Service Health to understand the impacted resources—of course, everyone should be able to consume this programmatically.
All of this will allow customers with large numbers of resources to know more precisely which of their services are impacted due to an outage, without having to conduct an investigation on their side. More importantly, customers can build alerts and trigger responses to these resource health alerts using native integrations to Logic Apps and Azure Functions.
Discoverability
Although we support both ‘push’ and ‘pull’ approaches for outage communications, we encourage customers to configure relevant alerts, so the right information is automatically pushed out to the right people and systems. Our customers and partners should not have to go searching to see if the resources they care about are impacted by an outage—they should be able to consume the notifications we send (in the medium of their choice) and react to them as appropriate. Despite this, we constantly find that customers visit the Azure Status page to determine the health of services on Azure.
Before the introduction of the authenticated in-portal Service Health experience, the Status page was the only way to discover known platform issues. These days, this public Status page is only used to communicate widespread outages (for example, impacting multiple regions and/or multiple services) so customers looking for potential issues impacting them don’t see the full story here. Since we rollout platform changes as safely as possible, the vast majority of issues like outages only impact a very small ‘blast radius’ of customer subscriptions. For these incidents, which make up more than 95 percent of our incidents, we communicate directly to impacted customers in-portal via Service Health.
We also recently integrated the ‘Emerging Issues’ feature into Service Health. This means that if we have an incident on the public Status page, and we have yet to identify and communicate to impacted customers, users can see this same information in-portal through Service Health, thereby receiving all relevant information without having to visit the Status page. We are encouraging all Azure users to make Service Health their ‘one stop shop’ for information related to service incidents, so they can see issues impacting them, understand which of their subscriptions and resources are impacted, and avoid the risk of making a false correlation, such as when an incident is posted on the Status page, but is not impacting them.
Most importantly, since we’re talking about the discoverability principle, from within Service Health customers can create Service Health alerts, which are push notifications leveraging the integration with Azure Monitor. This way, customers and partners can configure relevant notifications based on who needs to receive them and how they would best be notified—including by email, SMS, LogicApp, and/or through a webhook that can be integrated into service management tools like ServiceNow, PagerDuty, or Ops Genie.
To get started with simple alerts, consider routing all notifications to email a single distribution list. To take it to the next level, consider configuring different service health alerts for different use cases—maybe all production issues notify ServiceNow, maybe dev and test or pre-production issues might just email the relevant developer team, maybe any issue with a certain subscription also sends a text message to key people. All of this is completely customizable, to ensure that the right people are notified in the right way.
Parity
All Azure users should know that Service Health is the one place to go, for all service impacting events. First, we ensure that this experience is consistent across all our different Azure Services, each using Service Health to communicate any issues. As simple as this sounds, we are still navigating through some unique scenarios that make this complex. For example, most people using Azure DevOps don’t interact with the Azure portal. Since DevOps does not have its own authenticated Service Health experience, we can’t communicate updates directly to impacted customers for small DevOps outages that don’t justify going to the public Status page. To support scenarios like this, we have stood up the Azure DevOps status page where smaller scale DevOps outages can be communicated directly to the DevOps community.
Second, the Service Health experience is designed to communicate all impacting events across Azure—this includes maintenance events as well as service or feature retirements, and includes both widespread outages and isolated hiccups that only impact a single subscription. It is imperative that for any impact (whether it is potential, actual or upcoming) customers can expect the same experience and put in place a predictable action plan across all of their services on Azure.
Lastly, we are working towards expanding our philosophy of this pillar to extend to other Microsoft cloud products. We acknowledge that, at times, navigating through our different cloud products such as Azure, Microsoft 365, and Power Platform can sometimes feel like navigating technologies from three different companies. As we look to the future, we are invested in harmonizing across these products to bring about a more consistent, best-in-class experience.
Transparency
As we have mentioned many times in the Advancing Reliability blog series, we know that trust is earned and needs to be maintained. When it comes to outages, we know that being transparent about what is happening, what we know, and what we don’t know is critically important. The cloud shouldn’t feel like a black box. During service issues, we provide regular communications to all impacted customers and partners. Often, in the early stages of investigating an issue, these updates might not seem detailed until we learn more about what’s happening. Even though we are committed to sharing tangible updates, we generally try to avoid sharing speculation, since we know customers make business decisions based on these updates during outages.
In addition, an outage is not over once customer impact is mitigated. We could still be learning about the complexities of what led to the issue, so sometimes the message sent at or after mitigation is a fairly rudimentary summation of what happened. For major incidents, we follow this up with a PIR generally within three days, once the contributing factors are better understood.
For incidents that may have impacted fewer subscriptions, our customers and partners can request more information from within Service Health by requesting a PIR for the incident. We have heard feedback in the past that PIRs should be even more transparent, so we continue to encourage our incident managers and communications managers to provide as much detail as possible—including information about the issue impact, and our next steps to mitigate future risk. Ideally to ensure that this class of issue is less likely and/or less impactful moving forward.
While our industry will never be completely immune to service outages, we do take every opportunity to look at what happened from a holistic perspective and share our learnings. One of the future areas of investment at which we are looking closely, is how best to keep customers updated with the progress we are making on the commitments outlined in our PIR next steps. By linking our internal repair items to our external commitments in our next steps, customers and partners will be able to track the progress that our engineering teams are making to ensure that corrective actions are completed.
Our communications across all of these scenarios (outages, maintenance, service retirements, and health advisories) will continue to evolve, as we learn more and continue investing in programs that support these five pillars.
Reliability is a shared responsibility
While Microsoft is responsible for the reliability of the Azure platform itself, our customers and partners are responsible for the reliability of their cloud applications—including using architectural best practices based on the requirements of each workload. Building a reliable application in the cloud is different from traditional application development. Historically, customers may have purchased levels of redundant higher-end hardware to minimize the chance of an entire application platform failing. In the cloud, we acknowledge up front that failures will happen. As outlined several times above, we will never be able to prevent all outages. In addition to Microsoft trying to prevent failures, when building reliable applications in the cloud your goal should be to minimize the effects of any single failing component.
To that end, we recently launched the Microsoft Azure Well-Architected Framework—a set of guiding tenets that can be used to improve the quality of a workload. Reliability is one of the five pillars of architectural excellence alongside Cost Optimization, Operational Excellence, Performance Efficiency, and Security. If you already have a workload running in Azure and would like to assess your alignment to best practices in one or more of these areas, try the Microsoft Azure Well-Architected Review.
Specifically, the Reliability pillar describes six steps for building a reliable Azure application. Define availability and recovery requirements based on decomposed workloads and business needs. Use architectural best practices to identify possible failure points in your proposed/existing architecture and determine how the application will respond to failure. Test with simulations and forced failovers to test both detection and recovery from various failures. Deploy the application consistently using reliable and repeatable processes. Monitor application health to detect failures, monitor indicators of potential failures, and gauge the health of your applications. Finally, respond to failures and disasters by determining how best to address it based on established strategies.
Returning to our core topic of outage communications, we are working to incorporate relevant Well-Architected guidance into our PIRs in the aftermath of each service incident. Customers running critical workloads will be able to learn about specific steps to improve reliability that would have helped to avoid and lessen impact from that particular outage. For example, if an outage only impacted resources within a single Availability Zone, we will call this out as part of the PIRs and encourage impacted customers to consider zonal redundancies for their critical workloads.
Going forward
We outlined how Azure approaches communications during and after service incidents like outages. We want to be transparent about our five communication pillars, to explain both our progress to date and the areas in which we’re continuing to invest. Just as our engineering teams endeavor to learn from each incident to improve the reliability of the platform, our communications teams endeavor to learn from each incident to be more transparent, to get customers and partners the right details to make informed decisions, and to support customers and partners as best as possible during each of these difficult situations.
We are confident that we are making the right investments to continuing improving in this space, but we are increasingly looking for feedback on whether our communications are hitting the mark. We include an Azure post-incident survey at the end of each PIR we publish. We strive to review every response to learn from our customers and partners and validate whether we are focusing on the right areas and to keep improving the experience.
We continue to identify the inherent (and sometimes subtle) imperfections in the complex ways that our architectural designs, operational processes, hardware issues, software flaws, and human factors align to cause outages. Since trust is earned and needs to be maintained, we are committed to being as transparent as possible—especially during these infrequent but inevitable service issues.






















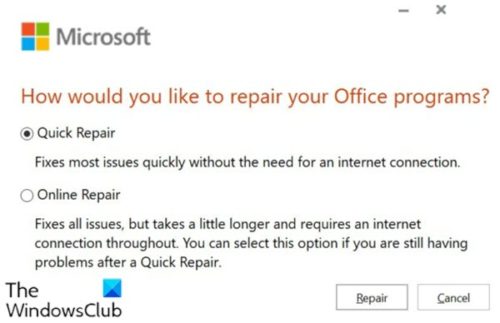
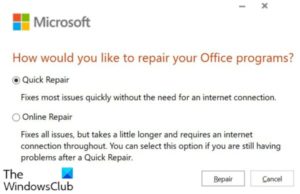 If you’re unable to repair Office 365 (now renamed as Microsoft 365) because the entire system is completely restricted and unable to reach the Programs […]
If you’re unable to repair Office 365 (now renamed as Microsoft 365) because the entire system is completely restricted and unable to reach the Programs […]